
Machine Learning, Artificial Intelligence, Neural Networks – der Hype um die Auswertung von Big Data nimmt kein Ende. Doch was ist maschinelles Lernen (ML) genau, wie kann maschinelles Lernen definiert werden, welche Algorithmen und Prozesse stehen dahinter, welche Tools werden eingesetzt? Was ist der Unterschied zwischen ML, Künstlicher Intelligenz und Deep Learning? Und wie ist die Abhängigkeit zu Big Data?
Diese und weitere Fragen möchten wir in diesem Artikel beantworten und anhand von Beispielen den Einsatz von maschinellem Lernen darstellen, dass klar verständlich ist, was Machine Learning ist, was es kann und wo auch die Grenzen sind.
Inhaltsverzeichnis
Infografik Machine Learning: Definition, Algorithmen und Beispiele

Was ist Machine Learning?
Einfach gesagt ist Machine Learning die Nutzung von Daten, um einen Algorithmus eine Entscheidung treffen zu lassen. Dies steht im Gegensatz zu regelbasierter künstlicher Intelligenz, bei der vom Mensch die Regeln für die Entscheidungsabfolge fix festgelegt wird.
Ein einfaches, oft wiederholtes Beispiel für diese Definition von Machine Learning ist ein Bilderkennungsalgorithmus, der zwischen Hund und Katze unterscheidet. Zuerst wird ein Modell mit Beispieldaten auf die Muster “Hund” und “Katze” trainiert, um danach neuen Inhalt (z.B. Bilder) in diese Kategorien einzuordnen.
Etwas genauer definiert ist Machine Learning der Einsatz von (großen) Datenmengen zur Generierung und Optimierung von Statistischen Modellen. Der Einsatz von Big Data erlaubt eine höhere Verlässlichkeit und Generalisierung des Modells, während die Bandbreite an Methoden für andere Anwendungsfälle (z.B. Kategorisierung, Vorhersage, Gruppierung, etc) geeignet ist.
Auf der anderen Seite ist Machine Learning nicht identisch mit dem Feld von künstlicher Intelligenz (KI) und auch nicht der autonom agierende Roboter, dem man gerne in der Popkultur begegnet. Machine Learning ist ein Teilfeld von KI, das sich auf das Lernen aus Erfahrung, also der Generierung von Wissen konzentriert. Dieses Lernen findet allerdings immer nur sehr stark auf eine Problemstellung bezogen statt.
Die autonomen Maschinen aus Film & Fernsehen hingegen werden “starke Künstliche Intelligenz” genannt, die nicht nur ein bestimmtes Problem abstrahieren und optimal lösen (= schwache Künstliche Intelligenz), sondern unverkennbar zum Leistungsspektrum des Menschen agieren können. Auf dieser Stufe der Entwicklung sind wir aus technischer Perspektive noch nicht, wie wir weiter unten in den häufigen Fragen erläutern.
Zusammengefasst ist Machine Learning der Einsatz von existierenden Daten, um diese als Erfahrung in einem statistischen Modell zu verallgemeinern. Dieses Modell wird auf unbekannte Daten angewandt, um ein Problem möglichst optimal zu lösen.
Welche Algorithmen werden im Machine Learning eingesetzt?
Generell gibt es drei Kategorien an Machine Learning Algorithmen. Supervised Machine Learning sind Methoden, um aus vorhandenen Daten zu lernen und darauf basierend neue Daten vorherzusagen. Unsupervised Learning beschäftigt sich mit der Identifikation von Mustern innerhalb von Daten, welche Einträge oder Verhaltensweisen ähnlich sind. Und Reinforcement Learning versucht einen möglichst optimalen Lösungsweg zu erlernen.

Supervised Machine Learning (Überwachtes maschinelles Lernen)
Einfach gesagt nutzt Supervised Machine Learning Informationen aus der Vergangenheit, um Muster zu lernen. Daher nennt man diese Kategorie von Machine Learning auch “Task-Driven Machine Learning”, da die Zielinformation bereits vorab definiert wird. In dieser Kategorie von maschinellem Lernen werden zwei Hauptarten von Algorithmen eingesetzt: Regression und Klassifikation.
Mittels Regression wird versucht, aus vergangenen Werten zukünftige vorher zu sagen. Ein einfaches Beispiel ist die Vorhersage von Umsatzzahlen basierend auf der Historie des Unternehmens. Das klassische Beispiel für Regressionsalgorithmen ist die Lineare Regression.
In der Machine Learning Classification, auf Deutsch Klassifikation, wird mittels sogenannter Labels (z.B. Bilder mit dem Label “Hund” oder “Katze”) dem Algorithmus mitgeteilt, in welche Kategorien er die Daten einteilen soll. Dies kann somit zur Kategorisierung neuer Information, zum Beispiel dem Erkennen von Produkten mit Fehlern in der Produktion, eingesetzt werden. Es gibt eine Bandbreite an Algorithmen für Classification-Probleme, unter anderem Entscheidungsbäume, Random Forests oder Neuronale Netze.
Diese Vorhersagen setzen immer ein Ziel voraus, zum Beispiel einen Wert oder eine Kategorie. Dies ist auch einer der Schwachpunkte: Um Daten zu verwerten, muss man teilweise erst hohe Aufwände betreiben, damit diese nutzbar werden. Der Vorteil von Supervised Machine Learning ist selbstverständlich die Möglichkeit, zukünftige Werte oder Ereignisse vorherzusagen.
Unsupervised Machine Learning (Unüberwachtes maschinelles Lernen)
Als Gegenstück arbeiten die Algorithmen des Unsupervised Machine Learning ohne bereitgestellte Information rein auf den Daten, weshalb man diese Kategorie auch “Data-Driven Machine Learning” nennt. Die Algorithmen dieser Kategorie versuchen Muster aus den Daten selbst zu extrahieren, um Gemeinsamkeiten, Ähnlichkeiten oder hohe Differenzen zu identifizieren. Es gibt drei Hauptarten von Algorithmen: Clustering, Recommender Systems und Dimensionality Reduction.
Der häufigste Algorithmustyp im unüberwachten maschinellen Lernen sind die Clusteranalysen. Hier werden Daten genutzt, um Ähnlichkeiten zwischen einzelnen Einträgen zu finden. Als Beispiel kann die Segmentierung von Kunden in Gruppen anhand von Clustering genannt werden. Es gibt eine Vielzahl an Clusteralgorithemen wie beispielsweise K-Means, DBSCAN oder agglomeratives Clustering.
Bei Recommender Systems werden häufig zusammen auftretende Ereignisse anhand von Regeln identifiziert und ausgewertet, um möglichst passende Entitäten zu identifizieren. Ein einfaches Beispiel ist eine Warenkorbanalyse im Supermarkt oder eCommerce: Indem man herausfindet, welche Produkte zusammen gekauft werden, kann man diese Information für Marketing- oder Positionierungsmaßnahmen nutzen. Ein weiteres Beispiel sind die zahlreichen Empfehlungssysteme von YouTube, Netflix und Konsorten. Eingesetzte Algorithmen sind vor allem kollaboratives Filtering und dessen Abwandlungen, aber auch andere Methoden von Assoziationsanalyse / Apriori werden eingesetzt.
Bleibt noch die Dimensionsreduktion (Dimensionality Reduction). Hierbei ist das Ziel, die Masse an vorliegenden Variablen auf ausschlaggebende, sogenannte Principal Components, zu reduzieren. Als Beispiel gilt der Anwendungsfall, wenn man andere Algorithmen wie eine Classification vorbereitet und seinen Variablenumfang auf relevante Variablen reduzieren möchte, um genauere Vorhersagen zu treffen. Eingesetzte Methoden sind zum Beispiel Principal Component Analysis (PCA) oder Linear Discrimination Analysis (LDA).
Zusammengenommen sind Unsupervised Machine Learning Algorithmen dort im Einsatz, wo keine Zielvariable (z.B. ein Wert oder eine Kategorie) definiert werden kann. Daher gilt es Muster in den Daten bezogen auf sich selbst zu erkennen, um Ähnlichkeiten zu identifizieren.
Reinforcement Learning (Verstärkendes oder Bestärkendes Lernen)
Beim Reinforcement Learning geht es darum, dass ein Agent (zum Beispiel ein Fahrzeug) in einem Environment (zum Beispiel ein Kurs) durch Feedback (zum Beispiel durch Drucksensoren) lernt, sein Verhalten zu optimieren, um ein Goal (zum Beispiel eine Ziellinie) zu erreichen. Wenn man also an künstliche Intelligenz denkt, bei der sich Roboter autonom bewegen können, kommt bestärkendes Lernen noch am nähesten. Algorithmisch gibt es eine Bandbreite an eigenen Regel-lernenden Vorgehensweisen wie Policy Optimization oder Q-Learning, aber auch der Einsatz von Supervised oder Unsupervised Machine Learning ist sehr gängig.
Aus unternehmerischer Sicht gibt es bis dato eher wenige Einsatzzwecke für Reinforcement Learning. Neben Mobilität, Wettalgorithmen, im Trading und im Pricing gibt es selten die hohe Frequenz an Ereignissen, die für ein selbstlernendes Verhalten notwendig ist. Auch der Entwicklungsaufwand ist verglichen mit den anderen Kategorien eher hoch, weshalb verstärkendes Lernen bis dato selten Anwendung findet.
Definition des ML Prozesses
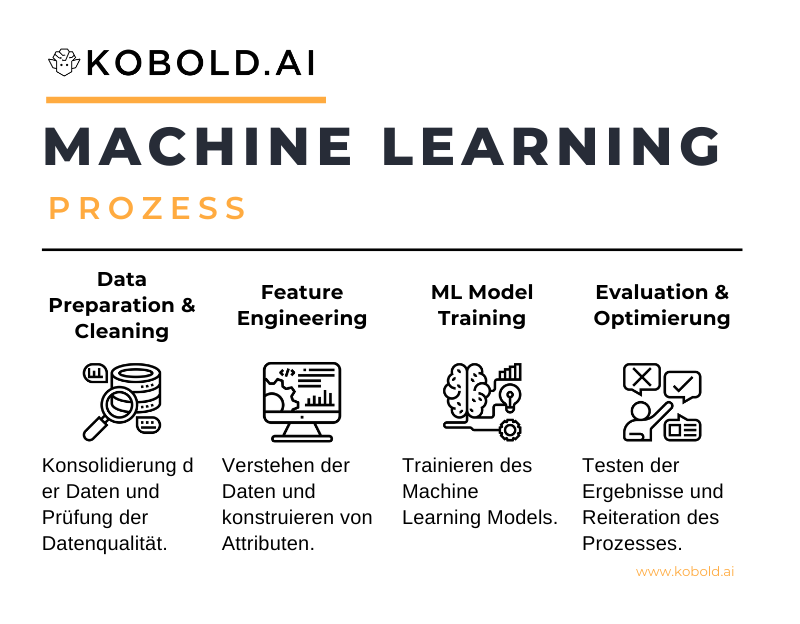
Vorbereitung
Strikt gesehen ist die Vorbereitung von Machine Learning kein Teil des eigentlichen Prozesses, sondern des Data Science Prozesses. Dennoch helfen die vorhergehenden Schritte, ein besseres Ergebnis in der eigentlichen Aufgabe – der Modellierung – zu erlangen. Als eine der zentralen Aufgaben von vielen Data Scientists gilt es daher, den Anwendungsfall (Use Case) in dem maschinelles Lernen angewandt wird zu verstehen. Diese Definition ist das Herzstück der Qualität der Arbeit: Nur wenn klar ist, welches Ziel verfolgt wird, kann auch der beste Algorithmus gewählt und entsprechend optimiert werden.
Der zweite Schritt ist oft in der Rolle des Data Engineers manifestiert: Die Sammlung und Bereitstellung der dafür notwendigen Daten. Ob direkt aus Quellsystemen, dem Data Warehouse, dem Data Lake oder auch erst durch frische Akquise: Die Daten für die Modellierung müssen erst organisiert werden. Auch hier gibt es wichtige Informationen über Herkunft, Inhalt und gegebenenfalls Erweiterbarkeit der vorliegenden Daten, die im späteren Prozess nützlich werden können.
Data Cleaning
Data Cleaning ist ein sehr relevanter Vorbereitungsschritt im Zuge von Machine Learning. Nur wenn die Daten von guter Qualität und auf (ungerechtigte) Ausreißer geprüft sind, können sie eingesetzt werden. Das sogenannte “Garbage in, Garbage out”-Prinzip beschreibt die Gefahr von schlechten Daten sehr einfach: Wenn man Daten einsetzt, die entweder nicht richtig erfasst, falsch aggregiert oder transformiert sind, wird das Ergebnis der Analyse oder des Models entsprechend falsch sein.
Übergeordnet ist Data Cleaning ein Teil von Data Stewardship und sollte als kontinuierlicher Prozess angewandt werden, statt nur zu Ad-Hoc Analysen. Dennoch hat der durchführende Data Scientist oder ML Engineer die Aufgabe, die Datenqualität abermals zu prüfen und ggf. zu korrigieren.
Feature Engineering & Feature Selection
Ist geprüft und festgestellt, dass die Daten einsatzbereich sind, gilt es als erstes – je Methode – ein sogenanntes Feature Engineering zu betreiben. Hier werden die vorliegenden Daten mittels Domänenwissen, Analyse und Data Mining untersucht, um aussagekräftige Metriken zu definieren und aus den Daten zu konstruieren. Zum Beispiel wird ein Feature namens “Datum” in ein Feature namens “Tage seit Kauf” umgeformt, um dieses für die Modellierung vorzubereiten. Somit werden aus Daten Informationen, indem Datensätze zusammengefügt, skaliert, konsolidiert oder eben neu berechnet werden.
Feature Engineering ist mitunter der wichtigste Teil im gesamten Prozess, denn hier wird der Input in das Modell definiert. Nur wenn Daten verarbeitbar vorliegen und aussagekräftig konstruiert werden, können sie zum Training des Modells genutzt werden. Folglich können nur dadurch sinnvolle Ableitungen geleistet werden und die Qualität der Vorhersage bzw. Kategorisierung steigt und sinkt entsprechend der konstruierten Features. Diese Variablen bilden die Grundlage, auf derer der eingesetzte Algorithmus lernt – also das vorhandene Wissen.
Mit einher geht die Auswahl der Metriken. Nicht nur die Konstruktion von validen Features, sondern auch die Selektion eines Teiles dieser Metriken ist eine sehr herausfordernde und wichtige Tätigkeit in Vorbereitung für die Modellierung. Je nach Algorithmus ist es mehr oder weniger notwendig eine hinreichende Feature Selection durchzuführen; doch sollte generell aufgrund der notwendigen Rechenleistung sehr gut durchdacht sein, welche Attribute man weiterverwendet.
Model Training
Wie man vielleicht an der Anzahl an Überschriften vor und nach diesem Punkt erkennen kann, ist das eigentliche Trainieren des Modells – auch wenn es der Kern von Machine Learning ist – der kleinste Schritt. Während vorab sehr umfangreich sowohl der Anwendungsfall und die darunter liegenden Daten durchdacht sein müssen, wird im Training grundsätzlich nur ein Algorithmus ausgeführt.
Nebst einfacher Anwendungsfälle, auf die nur ein Algorithmus trainiert wird, ist es inzwischen allerdings relativ herkömmlich, dass in diesem Schritt nicht nur eine Methode eingesetzt wird, sondern eine Bandbreite an möglichen Algorithmen getestet werden. Dies dient zur möglichst optimalen Vorhersage oder Kategorisierung, indem man die Ergebnisse des Trainings miteinander vergleicht und somit mit dem besten Modell weiterarbeitet.
Model Evaluation & Hyperparameter Optimierung
Hat man die Ergebnisse des Machine Learnings vorliegen, gilt es, diese Ergebnisse zu evaluieren. Je nach Methode werden hier unterschiedliche Vorgehensweisen eingesetzt. Von der Prediktion von Testdaten im Supervised Learning über manuelle Evaluation beispielsweise im Clustering gibt es eine Bandbreite an Möglichkeiten, die Performanz des Models zu evaluieren.
Durch diesen Test-Prozess sammelt man auch Informationen über mögliche Optimierungsansätze. Diesen Teil nennt man Hyperparameteroptimierung. Hierbei werden gewisse Einstellungen von Algorithmen, wie beispielsweise die Anzahl an Layern bei einem Deep Learning Ansatz oder die Anzahl an Clustern im Clustering, angepasst. Weiterhin ist es möglich, direkt wieder in den Bereich des Feature Engineerings & Selection zu gehen, um das Modell zu optimieren. Dieses zyklische Verhalten wird durchgeführt, bis man das beste Ergebnis erreicht hat.
Ausspielen der Information
Auch wenn mit dem Ergebnis der eigentliche Machine Learning Prozess beendet ist, ist die Aufgabe noch nicht beendet. Die Ausrollung der gewonnen Information bzw. das Modell möchte dann auch in Einsatz gebracht werden. Dies kann einerseits eine simple Visualisierung sein oder auch ein abschließender Workshop mit den Stakeholdern aus dem Business. Diese Abschlüsse sieht man vor allem bei Ad-Hoc Analysen oder internen Modellen.
Was einen anspruchsvollen nachfolgenden Prozess darstellt ist das Deployment eines produzierten ML Modells. Den Einsatz eines solchen Produkts in operationaler Umgebung, das sogenannte Deployment, erfordert Infrastruktur, Engineering und gutes Kanalmanagement, ist aber das definitive Ziel von Machine Learning in einem data-driven Unternehmen. Daher muss im Nachgang sowohl die Performanz als auch Verfügbarkeit des Modells überwacht werden.
Welchen Weg man auch wählt, ist wichtig, nicht nur die gewonnene Information zu vermitteln, sondern auch den Prozess durchsichtig zu gestalten. Welche Daten eingesetzt wurden, welche Probleme sich ergeben haben und weshalb ein bestimmtes Modell gewählt wurde – alles Informationen, welche für nachfolgende Projekte relevant sind.
Welche Tools werden im Machine Learning eingesetzt?
Programmier- / Skriptsprachen
Die häufigste Assoziation mit der Anwendung von maschinellen Lernen werden die Programmier-/Skriptsprachen python und R hervorrufen. Beide Sprachen sind durch ihre umfangreichen Paketbibliotheken in der Lage, eine Vielzahl an Algorithmen direkt bereit zu stellen, so dass sich mehr um die Umsetzung des Data Handlings und der Optimierungsroutinen gekümmert werden muss denn um die Implementierung selbst.
Doch selbst wenn diese beiden Sprachen den Markt dominieren, gibt es weitere, teilweise sehr spezialisierte Sprachen die mitspielen. Als Beispiele sind Scala und neuerdings auch Julia genannt. Während Scala im Vergleich mit Stabilität punktet, kann Julia als Compiler mit Schnelligkeit und Kompatibilität zu anderen Sprachen aufwarten.
Ob nun R, python, Scala oder Julia das richtige für Machine Learning ist, sei dahin gestellt. Meist ist es sehr starke persönliche Präferenz, welche Sprache zum Einsatz kommt. Zudem gibt es die allgemeine Empfehlung – um zumindest python und R zu unterscheiden – dass python trumpft, wenn es um das deployment, also das ausspielen von Modellen in die Unternehmensinfrastruktur, geht. Während in diesem Aspekt R schwächelt, hat es seine Stärken in der Bandbreite an verfügbaren Paketen sowie einer der besten Datenhandlingssyntaxen und seinen Visualisierungsoptionen.
(Data Mining) Tools
Nebst der Skriptsprachenmethode gibt es auch die GUI-basierte Variante, in der Nutzer in einem Interface einen ML Prozess erstellen können. Die beiden Platzhirsche sind wohl das kostenlose KNIME und das kostenpflichtige RapidMiner, wenn es um diese NoSkript-Methodik geht. Die Vorteile liegen auf der Hand: Anwender müssen weder Data Handling noch Machine Learning implementieren, sondern können einfach gemäß dem Baukastenprinzip ihre Abläufe zusammenklicken. Dies entspricht einer gewissen Demokratisierung von ML, also der Verringerung von notwendigen Fachwissen für die Umsetzung. Die Nachteile sind ebenso klar: Die Feinjustierung, das Deployment und die Integration in andere Applikationen sind nicht die Stärken von Data Mining Tools.
Cloud
Durch die immer breitere Anwendung von maschinellem Lernen und die Notwendigkeit für sehr große Rechen- und Speicherkapazitäten beim Einsatz von Big Data sind die Cloud Services verschiedener Anbieter entstanden. Inzwischen versuchen die meisten dieser Vendoren nicht nur Teilbereiche des Data Science Bereichs mit ihrem Angebot abzudecken, sondern stoßen immer weiter in die operativen Bereiche vor. So gibt es üblicherweise von Data Engineering Tools über Cloud Computing sehr wohl auch ML Applikationen in der Cloud.
Unterschieden wird im Prinzip zwischen drei Methoden: Einerseits ist es möglich, einfach eigenen Code in der Cloud laufen zu lassen. Hier kann zum Beispiel ein python-Programm hochgeladen und entsprechend deployed werden. Die zweite Möglichkeit ist der Einsatz von GUI-basierten, vorgefertigten Algorithmen. Diese ML-Apps sind sehr häufig im Bereich Cognitive Computing, also der Sprach- und Bildverarbeitung, zu finden, erobern zunehmends aber auch klassischere Bereiche des maschinellen Lernens. Die dritte Variante ist der Einsatz von Automatisierten Machine Learning (AutoML). Wie weiter unten detailliert erläutert, ist hier der Ansatz, große Teile des Prozesses automatisiert mittels selbstoptimierten Algorithmen umzusetzen.
Andere Software
Es gibt heute kaum mehr eine Software, die sich nicht Machine Learning oder zumindest Künstliche Intelligenz auf die Fahnen schreibt. Folglich erübrigen wir uns an dieser Stelle, eine Liste mit hunderten von Software-Anbietern zu veröffentlichen. Dieser Trend lässt jedoch auf eins schließen: Es gibt eine sehr hohe Bandbreite an Anwendungsfeldern für Machine Learning und der Einsatz von maschinellem Lernen ist inzwischen Normalität geworden. Wer dennoch ein wenig Nachforschung auf Software-Basis betreiben möchte, dem sei folgende Übersicht ans Herz gelegt:
Beteiligten Rollen im ML Prozess
Am gesamten Machine Learning Prozess sind sehr viele Personen und Rollen beteiligt. Hier möchten wir stichpunktartig auf die Aufgaben und Einflüsse der verschiedenen Rollen eingehen.
Business Stakeholder
Das Business ist der verlängerte Arm des Kunden. Daher sind Business Stakeholder vor allem im Bereich der Anforderung und Use Case Definition von hoher Bedeutung, damit kundenzentriert gearbeitet werden kann. Die Business Stakeholder bereichern den Machine Learning Prozess durch:
- Einbringung der Bedürfnisse des Kunden
- Beisteuerung von Erfahrungswerten
- Definition von strategischer Wichtigkeit von Use Cases
Data Analyst
Während Datenanalysten per se kein Machine Learning betreiben, können sie dennoch im Prozess beteiligt sein. Vor allem in der Voranalyse, dem Feature Engineering oder der Visualisierung von Ergebnissen liegen die Stärken der Data Analysts. Folglich tragen Data Analysts folgendermaßen zum ML Prozess bei:
- Beisteuerung von Erfahrung bzgl. Datenquellen und deren Einsatz
- Extraktion von Daten aus dem Data Warehouse
- Vorbereitung von Daten, z.B. Feature Engineering
Data Engineer
In größeren und professionellen Teams ist der Data Engineer für die Dateninfrastruktur und deren Nutzung zuständig. Konkret umfasst dies Datenbankmanagement, die Erstellung von Data Pipelines und die Extraktion und Übermittlung von notwendigen Daten. Da dies eine der aufwendigsten Aufgaben im gesamten Data Science Prozess ist, füllt der Data Engineer eine der wichtigsten Rollen indem er folgende Aufgaben übernimmt:
- Akquise und Anbindung von Datenquellen
- Management von (Cloud-)Infrastruktur
- Bereitstellung von Daten oder Datenextrakten
Unser Artikel “Data Engineer: Beschreibung, Aufgaben, Tools und Gehalt” geht auf Details zur Rolle Data Engineer ein.
Data Scientist
Der Data Scientist ist der Hauptakteur in Bereich von Machine Learning. Neben den vorhergehenden und nachfolgenden Prozessen ist er derjenige, der die verschiedenen Methoden des maschinellen Lernens einsetzt und optimiert. In kleineren Teams verantwortet er zusätzlich Themen des Data Engineers und nachfolgende Prozesse wie die Visualisierung oder das Deployment. Zusammengefasst betreibt der Data Scientist:
- Definition des Anwendungsfall und passender Algorithmen
- Datenvorbereitung und -analyse
- Machine Learning und Optimierung
Unser Artikel “Data Scientist: Beschreibung, Aufgaben, Tools und Gehalt” geht auf Details zur Rolle Data Scientist ein.
ML (Optimisation) Engineer / Specialist
Die wohl seltenste, weil auch spezialisierteste Rolle in dieser Liste: Der ML Engineer oder ML Specialist. Diese Rolle setzt sich vom generellen Data Scientist durch ihren klaren Fokus auf die Erstellung und vor allem Optimierung der Modelle ab. Während der Data Scientist meist noch andere Prozesse der Daten mitverantwortet, ist beim ML Engineer eine ganz klare Fokussierung zu finden:
- Definition und Implementierung von Modellen
- Ggf. Neu- oder Weiterentwicklung von Machine Learning Methoden
- Hyperparameteroptimierung und Generalisierung
Data Translator / Data Ambassador
Die letzte Rolle beschäftigt sich mit dem Informationsübertrag zurück in Richtung Domäne. Maschinelles Lernen ist fachlich kompliziert und oft sind kleine Unterschiede im Einsatz oder den Ergebnissen schwierig zu abstrahieren, um sie fachfremden Stakeholdern zu erklären. Hier kommen Rollen wie der Data Translator oder der Data Ambassador zum Einsatz: Sie bilden das Bindeglied zum Business, um Idee, Prozess und Ergebnis zu vermitteln:
- Aufnahme von Anforderungen seitens der Domäne / des Business
- “Übersetzung” von Anwendung und Resultat von Machine Learning Initiativen
- Ansprechpartner für Unklarheiten zwischen Fachbereich und Domäne
Abgrenzung von maschinellen Lernen
Es ist oft Unklarheit, wie Machine Learning in Relation zu vielen verwandten oder naheliegenden Begriffen zu verorten ist. Daher hier eine kurze Übersicht über die gängigsten Begriffe, die oft im Zusammenhang mit maschinellem Lernen gebraucht werden:
Machine Learning vs. Data Analytics / Datenanalyse
Generell gilt, dass ein Data Analyst keine Advanced Analytics oder Data Science betreibt. Data Analysts sind meist per Definition auf die grundlegende statistische, also deskriptive Analyse von Daten beschränkt. Häufige Anwendungsfälle sind zum Beispiel die Visualisierung von Daten aus dem Data Warehouse oder im Bereich von Webanalytics.
Inzwischen verschwimmen die Grenzen von Data Analytics und Machine Learning immer mehr. Dass die Vorabanalyse ein sehr wichtiger Bestandteil von Machine Learning (Feature Engineering) ist, ist dabei nur ein Argument. Es gibt auch immer mehr Data Analysts die ML-Methoden einsetzen – und somit sich mehr in Richtung maschinellem Lernen entwickeln, als ursprünglich für den Begriff vorgesehen.
Machine Learning vs. Data Science
Machine Learning ist eine Methode im Bereich Data Science. Data Science betitelt den gesamten Prozess des Dateneinsatzes – von Use Case Definition über Datenakquise und dem Einsatz von Analytics und ML bis hin zum Ausspielen des Wissens oder des Modells.
Machine Learning vs. Künstliche Intelligenz (KI) / Artificial Intelligence (AI)
Machine Learning ist ein Teilgebiet der künstlichen Intelligenz. Generell umfasst KI alle algorithmischen Methoden, die menschliches Verhalten nachahmen. Folglich fallen auch regelbasierte Systeme ins Gebiet der Artificial Intelligence, wie zum Beispiel ein Tic-Tac-Toe Bot. Machine Learning hingegen ist das statistische Lernen von Mustern, ohne von festgelegten Regeln zu profitieren.
Machine Learning vs. Neuronale Netzwerke (NN)
Neuronale Netzwerke sind eine Methode im Machine Learning, die für eine Bandbreite an Anwendungsfällen (z.B. Klassifikation, Vorhersagen, Clusteranalysen) eingesetzt werden. Daher sind neuronale Netzwerke nur eine Ausprägung von Machine Learning, aber eine die zunehmends an Bedeutung gewinnt, da sie einen Teil des Feature Engineerings und der Feature Selection integriert haben können und somit nicht mehr durch den Data Scientist durchgeführt werden müssen.
Machine Learning vs. Deep Learning (DL)
Deep Learning ist eine besondere Art von Neuronalen Netzwerken, die mehrere Ebenen (Layer) beinhaltet. Dies erlaubt für besonders abstrahierte Information aus den Eingabedaten, die sich über mehrere Ebenen verfeinert. Hierarchisch gesehen ist somit Künstliche Intelligenz das Feld, ML eine Herangehensweise, Neuronale Netze eine Methode und Deep Learning eine Art der Implementierung.
Machine Learning vs. Big Data
Machine Learning funktioniert prinzipiell auch mit kleinen Datenmengen, durch großes Volumen an Daten erhöht sich aber die Robustheit und somit die Aussagekraft von Modellen. Folglich befeuert Big Data seit Jahren den Einsatz von maschinellem Lernen und oft ist zu hören, dass nur durch Big Data Machine Learning erst möglich ist. Daher verbindet die beiden Begriffe eine sehr enge Freundschaft, denn große Datenmengen sind meist nur mit Machine Learning auswertbar, während Machine Learning durch Big Data qualitativ höherwertig wird.
Machine Learning vs. Data Mining
Data Mining bezeichnet die Untersuchung von vorliegenden Daten auf neue Muster. Bei diesem Herangehen werden sehr häufig neben deskriptiver Statistik und Inferenzstatistik auch Machine Learning Methoden eingesetzt. Daher sind Data Mining und Machine Learning nicht äquivalent, aber Data Mining nutzt Methoden maschinellen Lernens. Für Details zum Unterschied und den Ideen hinter Data Mining eignet sich unser Artikel “Data Mining: Definition, Methoden und Tools”.
Predictive vs. Prescriptive Analytics
Predictive Analytics beschreibt den Teil der Vorhersage von Machine Learning Produkten. Prescriptive Analytics auf der anderen Seite ist eine Reihe von Vorhersagen, aus deren Kombination oder Vergleich eine eine Aktion empfohlen oder sogar durchgeführt wird. Daher ist Prescriptive Analytics der Einsatz des Ergebnisses eines oder mehrerer Modelle, während Predictive Analytics das Ergebnis nur erarbeitet.
Gefahren und Grenzen von Machine Learning
Nebst all dieser interessanten Applikationen und technischen Aspekte, gibt es auch einige ganz klare Gefahren beim Einsatz von Machine Learning. Diese Gefahren beziehen sich einerseits darauf, dass das Ergebnis des Algorithmus nicht die Realität wiederspiegelt, andererseits auf ein übermäßiges Verlassen auf die Ergebnisse eines Modells.
Bias
Wie mehrfach angemerkt ist einer der Hauptbestandteile im maschinellen Lernen die Definition der zu nutzenden Daten. Nur indem maschinelles Lernen Daten in Wissen transformiert, ist es möglich, davonGeneralisierungen abzuleiten. Dies birgt zwei Gefahren: Einerseits besteht die Gefahr, dass man durch falsche Datenwahl den Algorithmus unbewusst vorbeeinflusst. Dies ist häufig der Fall, wenn keine nutzerzentrierte Research vorab geleistet wird, sondern der Machine Learning Engineer aus seiner Fachexpertise versucht, die beeinflussenden Daten zu definieren. Ein weiterer Faktor ist, dass einfach nur eine bestimmte Bandbreite an Daten zur Verfügung steht, diese aber nicht notwendig mit der höchsten Kausalität im Einklang stehen müssen.
Die zweite Gefahr ist ein Bias durch die Historie der Daten selbst. Gibt es in dem genutzten Daten, also der Vergangenheit, ein Muster das sehr prägnant ist, wird dies auch im Modell zu finden sein, obwohl dies gegebenenfalls nicht beabsichtigt ist. Als bestes Beispiel kann man den Einsatz der verschiedenen Recruiting-Algorithmen im FAANG-Umfeld sehen. Weder Amazon noch Google schaffen es, ihre Machine Learning basierten Lebenslauf-Evaluationen frei von Sexismus zu konstruieren.
Datenqualität
Wie bereits im Data Cleaning angesprochen ist die Datenqualität der eingesetzten Daten fundamental für die Qualität des Outputs. Leider werden sehr oft Daten falsch transformiert, sind fehlerhaft oder zu ungenüge dokumentiert. Auch fehlen oft zentrale Daten, um einem Modell die Aussagekraft zuzuweisen, die es verdient.
Folglich ist eine der Gefahren, Entscheidung auf Basis falscher Daten und somit falscher Modelle zu treffen. Dieses Thema mündet in der Anforderung von Data Governance & Data Management, um die Grundlage für verlässliche Machine Learning Implementierungen zu bilden.
Blackbox
Eine häufig vorgebrachte Kritik ist, dass gewisse ML Algorithmen eine Blackbox darstellen. Vor allem im Bereich der Neuronalen Netze ist durch die schiere Vielfalt an Teilergebnisse (Gewichten) und Parametern gar nicht mehr oder nur unter immensem Aufwand nachvollziehbar, weshalb ein Modell eine Entscheidung trifft. Dies führt zur Vertrauensfrage: Warum trifft der Machine Learning Algorithmus eine Entscheidung?
Gelinde gesagt ist die Blackbox Metapher auch in heutigen Systemen von Relevanz. Die Interpretierbarkeit hat sich verbessert und immer mehr Methoden entstehen, um die inneren Abläufe von Algorithmen zu definieren, aber nicht immer sind einzelne Prozessschritte absolut durchsichtig.
Aber – und diese Kritik muss sich diese Frage gefallen lassen – in vielen Fällen ist ein absolutes Verständnis nicht notwendig. Solange Die Datenqualität des Inputs stimmt, das Modell richtig implementiert ist, ist nur der Output wichtig – so die Argumentation mancher Kritiker. Und dies trifft sicherlich für einen Großteil der Anwender zu, andere Rollen wünschen sich hingegen noch mehr Klarheit über die Abläufe und Stati.
Overfitting
Da die Modellierung von maschinellem Lernen die Optimierung eines statistischen Modells darstellt, ist meist als Ziel ein “optimales Modell” angegeben. Vor allem im supervised Learning werden die Hyperparameter meist so lange angepasst, bis die geringste Fehlerrate im Test-Set zu observieren ist.
Während dies den Eindruck verschafft, dass das Modell die Realität immer besser abbildet, kann genau das Gegenteil der fall sein. Dieses Overfitting ist die Anpassung des Modells an die Trainings- und Testdaten, bis sie optimal die vorliegenden Daten abdecken, aber auf neuen Input schlecht reagieren. Daher gilt es Overfitting zu vermeiden während man die Optimierung vorantreibt.
Beeinflussung / Mistraining
Wer die Abläufe hinter Machine Learning versteht, kann auch Rückschlüsse auf die implementierten Algorithmen eines Produkts schließen. Folglich ist auch bekannt, wie das Training und die Optimierung von Statten geht. Dies erlaubt auch Nutzern, bewussten Einfluss auf die Ergebnisse zu nehmen. Im einfachen Fall ist dies die Beeinflussung von Google Suchergebnissen oder YouTube-Videos. Im schwierigeren Fall erlaubt dies den Nutzern, auch öffentliche Ergebnisse zu beeinflussen – wie im Fall “Tay” geschehen.
Beim Chatbot Tay, der über Twitter kommunizierte, schafften es andere Twitternutzer, dass Tay nicht mehr wie ein Jugendlicher, sondern wie ein Rassist und Seist sprach. Dies geschah durch einfaches Mitraining und führte zum Abschalten des Bots seitens Microsoft. Zusammengefasst muss man sich viele Gedanken machen, welche Schnittstellen und Einflussmöglichkeiten man Nutzern genehmigt.
Häufige Fragen zu Machine Learning (FAQ)
Wird Machine Learning die Menschen ersetzen?
Dies ist eine vieldiskutierte und eher philosophische Fragen. Im generellen kann man sagen, solange es keine starke / generelle AI gibt, ist die Komplexität des menschlichen Gehirns auch nicht in Gefahr. Und selbst falls es diese gibt, gibt es noch viele offene Fragen. Vom Lernen über Langfristplanung bis zur Frage über die Hardware – viele Aspekte, über die man fachsimpeln könnte.
Generell gesagt stellt Machine Learning daher bisher keine Gefahr für die Menschen und deren Arbeit dar. Selbstverständlich werden manche Aufgaben automatisiert werden, aber dies ist natürlich im digitalen Wandeln. Der viel wichtigere Aspekt ist eher, dass maschinelles Lernen eine höhere Effizienz und Genauigkeit erlaubt und daher die eigene Arbeit verbessert. Daher sollte maschinelles Lernen und andere Methoden nicht als Gefahr oder Gegner gesehen werden, sondern eher als Methode und Partner in der Zukunft.
Wie kann ich Machine Learning lernen?
Es gibt inzwischen eine Vielzahl an Möglichkeiten Machine Learning, oder als übergeordnete Thematik Data Science, zu lernen. Von Büchern über Universitätsabschlüsse bis zu unzähligen Onlinekursen: es führen viele Wege zu den Daten. Unsere persönliche Empfehlung ist jedoch, möglichst früh praktische Erfahrung zu sammeln, damit man mit den realen Problemen – wie einer schlechten Datenqualität – konfrontiert wird.
Was braucht ein Unternehmen für den Einsatz von ML?
Erste Erfahrung mit Machine Learning kann jedes Unternehmen relativ simpel sammeln. Entweder indem man einen Data Scientist einstellt oder eine externe Agentur beauftragt, erste Anwendungsfälle umzusetzen. Diese Maßnahmen können aber höchstens einen Vorgeschmack geben, für nachhaltige Umsetzung und strategische Nutzung von Machine Learning müssen viele Aspekte beachtet werden. Von Schaffung der Organisation, Besetzung der Rollen, über Erschließung und Bereitstellung einer Bandbreite an Datenquellen bis zur Data Governance: ML Modellierung, vor allem in agiler Arbeitsweise, fordert eine Bandbreite an Maßnahmen.
Welche Vorteile bringt maschinelles Lernen für ein Unternehmen?
Dies ist eine sehr breite und hochindividuelle Frage. Grob gesagt kann man Machine Learning in zwei Kategorien anwenden: Operationale Optimierung oder Innovation. Ersteres umfasst so ziemlich alle Prozesse eines Unternehmens, die mittels KI (teil-)automatisiert werden oder zusätzliche Information und Muster identifizieren. Die zweite Kategorie ist der Einsatz von Daten darüber hinaus: Entweder durch die Schaffung neuer innovativer Methoden der Arbeit oder sogar in der Schaffung von neuen (digitalen) Geschäftsmodellen.
Während nicht jedes Unternehmen den gleichen Nutzen und Effekt vom Einsatz von ML hat, wird es mit den kommenden Jahren dennoch zunehmend obligatorisch werden, die Methodik einzusetzen. Egal welche Organisation, egal welches Unternehmen: Es werden immer mehr Daten über Verhalten, Prozesse und Produkte generiert und die Auswertung wird zunehmend komplexer werden. Folglich macht es für jedes Unternehmen Sinn, sich Gedanken darüber zu machen welche Vorteile Machine Learning für das eigene Unternehmen bringen kann – und wie man diese Vorteile erarbeiten kann.
Ist automatisiertes Machine Learning (AutoML) die Zukunft von Machine Learning?
Wenn wir vom gesamten Machine Learning bzw. Data Science Prozess sprechen, dann mit Sicherheit nicht. Das Verstehen von Anwendungsfällen, das Erarbeiten von Lösungsstrategien und auch zwischenmenschliche Komponenten von Datenrelevanz werden automatisierte ML Tools in naher Zukunft nicht können. Geht es um den puren Machine Learning Implementierungs- und Optimierungsprozess, gibt es eine sehr reale Chance, dass AutoML bald mindestens mit dem Mensch mithalten kann. Von Feature Engineering über Modellselektion sind AutoML Plattformen ein vielfaches schneller und optimierter als von Hand geschriebene Algorithmen, weswegen sie auch zunehmend attraktiver werden.
Ist Machine Learning das Wichtigste in einer Data Driven Company?
Da die Idee, mit Daten zu arbeiten eine Frage der Kultur, nicht von Algorithmen ist, ist die Antwort auf diese Frage: Nein. Machine Learning ist ein fundamentaler Teil von Data Science, von datenbasierten Arbeiten, aber lange nicht das einzigste. Da sich der Weg einer Data Driven Company aus vielen Aspekten, wie einer sauberen Data Governance, dem Data Engineering oder auch einer Kundenzentrierung zusammensetzt, kann man Machine Learning als Methode nicht als den wichtigsten Teil deklarieren.
Liste an Begrifflichkeiten und Abkürzungen im Machine Learning
| Artificial Intelligence (AI) / Künstliche Intelligenz (KI) | Die Simulierung von menschlichen Verhalten. |
| Machine Learning (ML) / Maschinelles Lernen | Die Nutzung von datenbasierten Algorithmen um Muster zu erkennen. |
| Neuronale Netze (NN) / Neural Networks | Eine Form von Machine Learning, in der Neuronen simuliert werden um von Input Output abzuleiten. |
| Predictive Analytics(Prädiktion) | Einsatz von Machine Learning um Werte oder Kategorien vorherzusagen. |
| Prescriptive Analytics | Einsatz von Machine Learning um Handlungsempfehlungen zu geben. |
| Unsupervised Machine Learning | Zusammengehörigkeit und Muster innerhalb von Daten finden, ohne vorab Zielinformation zur Verfügung zu stellen. |
| Supervised Machine Learning | Training von Vorhersagemodellen anhand Beispieldaten. |
| Use Case | Ein Anwendungsfall. |
| Big Data | Große oder variable Datenmengen. |
| Data Science / Datenwissenschaft | Der Einsatz von Daten zur Optimierung oder Generierung von Wissen. |
Beispiele für Machine Learning Anwendungsfälle
Predictive Maintenance in de Industrie 4.0
Die Vorhersage vom drohenden Ausfall von Maschinen ist seit geraumer Zeit einer der interessanten Anwendungsfälle im industriellen Kontext. Mittels historischer Daten werden Ausfälle von Maschinen detektiert und durch ein Modell zukünftige Ausfälle vorhergesagt. Dies führt zu verbesserten Wartungszyklen, kaum Ausfallzeiten und optimaler Auslastung.
Kundensegmente durch Clustering
Seine Kunden besser zu verstehen ist zentral für jedes Unternehmen. Indem man Unsupervised Machine Learning, insbesondere Clustering Algorithmen, einsetzt, kann man besser die Ähnlichkeiten zwischen Kundengruppen mittels derer Attribute und Verhalte quantifizieren. Dies führt zu datenbasierten Kundengruppen, die entsprechend weiterführend verarbeitet und gepflegt werden können.
Empfehlungssystem von Netflix
Empfehlungssysteme bilden die Basis für ein höheres User Engagement – also wie lange ein Nutzer zum Beispiel eine Website nutzt. Einem Nutzer passende nächste Inhalte anzuzeigen fusst auf Recommendation Algorithmen, bei denen Ähnlichkeiten zwischen Nutzern oder Videos genutzt werden, um Empfehlungen zu geben. Dies führt zu einer individuellen Inhaltsanzeige, was den Nutzern die Inhalte anbietet, die möglichst interessant sind.