Ähnliche Dinge zu finden ist oft nicht einfach. Vor allem in einer immer größer werdenden Flut von Daten ist es herausfordernd, ähnliche Gruppen zu identifizieren. Zum Glück kann künstliche Intelligenz helfen: Durch Clustering.
Was ist Clustering?

Clustering ist ein Algorithmus aus dem Bereich der künstlichen Intelligenz. Diese Art von Algorithmus wird eingesetzt um ähnliche Daten in Gruppen zu fassen. Die Idee ist, dass man zu jedem Eintrag möglichst ähnliche andere Einträge identifiziert und daraus sogenannte Cluster formt. Wie das genau funktioniert und welche Einsatzzwecke es dafür gibt, erklären wir in den nächsten Abschnitten.
Was ist künstliche Intelligenz?
Künstliche Intelligenz bedeutet, dass Maschinen menschliches Verhalten simulieren. Die Spanne hierbei reicht von einfacher, regelbasierter Systeme (z.B. ein programm das immer den besten Lagerplatz in einem Lager findet) zu Machine Learning, das selbst Muster erkennt und anwenden kann um Vorhersagen über die Zukunft zu treffen.
Clustering ist ein Algorithmus im Bereich des maschinellen Learning, genauer des unüberwachten Lernens (engl. Unsupervised learning). Unüberwachtes lernen bedeutet, dass rein aus Daten und deren Strukturen Muster abgeleitet werden. Im Gegensatz dazu steht überwachten lernen (supervised learning), bei dem Zielvariablen vorgegeben werden, anhand derer ein Modell für Vorhersagen abstrahiert wird.
Beispiele für supervised learning Algorithmen sind Klassifikation (z.b. Ausschuss an einer Produktionsstraße erkennen) und Regression (z.B. Vorhersage von Umsatz). Beispiele im Bereich unsupervised learning sind empfehlungssysteme (z.B. im E-Shop) und eben Clustering.
Wie funktioniert Clustering?
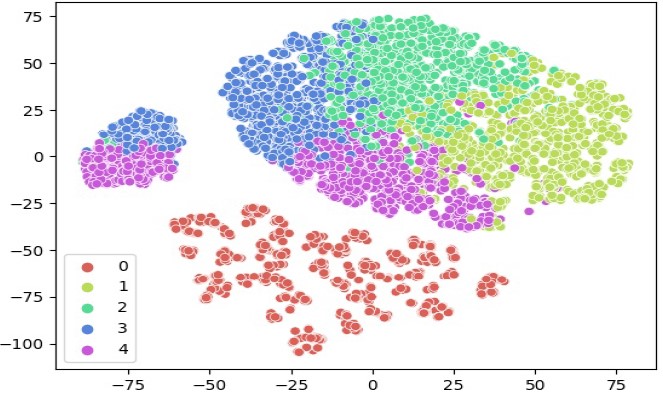
Wie eingangs erwähnt dient Clustering zur Identifikation von Gruppen. Da Clustering im Gegensatz zu anderen Algorithmen (z.B. Klassifikation) kein Vorwissen über siw Zielgruppen besitzt, ist es die Aufgabe des Algorithmus, in den Daten eigenständig Muster zu identifizieren.
Diese Muster beruhen darauf, dass für jeden Eintrag in einem Datensatz möglichst ähnliche Einträge gefunden werden. Dabei gibt es verschiedene Methoden um Ähnlichkeit zu definieren. Der einfachste Fall ist eine kontinuierliche Skala (z.B. Größe) bei der Werte bei geringen Abstand näher und somit ähnlicher sind (z.B. kleine Menschen).
Führt man dieses Beispiel nun fort, werden selbstverständlich auch die Ähnlichkeit zwischen Kategorien oder Text eingesetzt, um Gruppen zu clustern. In unserem Fall wären das Geschlecht oder eine email entsprechende Möglichkeiten, heraus zu finden, welche Daten dich ähnlicher sind.
Stellt man sich dieses Vorgehen auf größeren Datenmengen vor (z.b. einem CRM oder den Transaktionsdaten eines e commerce shops), formt man schnell Gruppen aus den Daten, die eine möglichst hohe Übereinstimmung in ihren Attributen aufweisen.
Was ist Kobold AI?
Kobold AI bietet den Einsatz künstlicher Intelligenz ohne technisches Vorwissen. Einfach, schnell und günstig KI anwenden, um Mehrwert durch Daten zu generieren.
Wie es funktioniert erklärt unser interaktives Video:
Wie können identifizierte Cluster eingesetzt werden?
Hat man einmal Cluster identifiziert, gibt es mehrere Arten und Weisen diese dann einzusetzen um Mehrwert zu generieren. Hier die beiden häufigsten Einsatzzwecke: gefundene Gruppen nutzen und Ausreißer erkennen.
Gruppen finden: Komplexität reduzieren
Der häufigste Einsatzzweck von Clustering ist die Identifikation von Gruppen um Komplexität der Daten zu reduzieren. Indem man ähnliche Daten zusammenfasst, kann man Varianz abstrahieren und viele Entitäten (zum Beispiel Kunden oder Ereignisse) auf wenige Gemeinsamkeiten reduzieren.
Als Werkzeug kann dies dann in sowohl Strategie als auch operativer Abwicklung eingesetzt werden: Besser verstehen oder einfacher verarbeiten sind klare Optionen, sobald man Komplexität durch Clustering reduziert hat.
Ausreißer erkennen: Falls was nicht stimmt
Während die Vorgehensweise die gleiche bleibt, kann man die Erkenntnis und somit die Aktionen auch umkehren. Indem man also Gruppen identifiziert, identifiziert man auch Einträge die weit weg von den Gruppen sind – sogenannte Ausreißer.
Ausreißer denotieren also Dateneinträge, die außergewöhnlich sind. Ist unsere Aufgabe, dass die Daten erwartbar und wiederholbar sind, sind Ausreißer eher kritisch zu betrachten. Somit wird sich nicht auf die identifizierten Gruppe(n) konzentriert, sondern auf jene Datensätze die nicht in den Gruppen sind – und wieso.
Beispiele für die Anwendung von Clustering
Von der Theorie in die Praxis: Im Folgenden möchten wir drei konkrete Beispiele vorstellen, wie Clustering in Unternehmen angewandt werden kann.
Data-Driven Personas
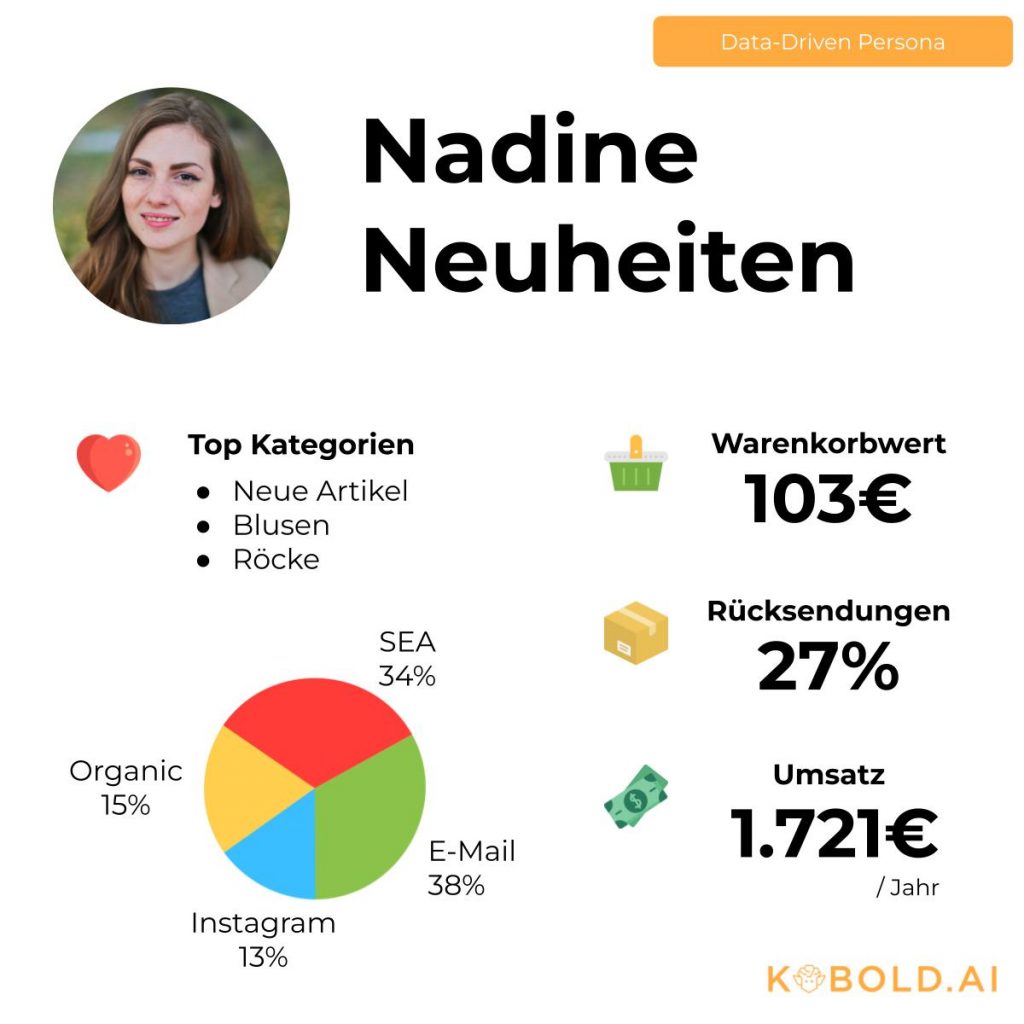
Einer der kreativen Einsatzzwecke für Clustering ist die Identifikation und Beschreibung von Kunden-Clustern, um Data-Driven Personas zu erstellen. Eine Persona ist eine steckbriefartige Repräsentation einer Kundengruppe, die qualitativ beschrieben ist. Nutzt man nun statt Interviews und Experten-Wissen Daten als Grundlage, bekommt man eine datenbasierte, verlässliche Gruppierung, die direkt in die Systeme eingespeist werden kann.
Als Input dienen Kundenstammdaten (z.B. CRM), aber auch Verhaltensdaten (z.B. Transaktionen aus dem Online-Shop oder Service-Anfragen). Zusammengenommen ergibt dies je Kunde eine “Beschreibung”, wie sich dieser in Kontakt, Einkauf, Reklamation etc. verhält.
Werden nun alle Kunden anhand dieser Attribute zu Gruppen zusammengefasst, erlaubt Clustering eine sehr konkretes, angewandtes Verstehe der eigenen Kunden und wie für diese personalisiert werden kann. Einsatzzweck sind strategische Planung, Produktentwicklung, Service-Gestaltung aber auch sehr praktische Dinge wie Newsletter-Personalisierung nutzen Data-Driven Personas.
Während unser erstes Beispiel auf Kundendaten arbeitet, nutzt unser zweites Beispiel Produkt-Stammdaten aus einem Produktinformationssystem (PIM, MDM, PDM, PLM,..). Die Idee ist, dass man Clustering einsetzt, um möglichst ähnliche Produkte zu Gruppen zusammenzufassen. Da diese Gruppen auf bestimmten Attributen basieren (zum Beispiel Material, Größe), teilen sie Gemeinsamkeiten und erlauben für eine abstrahierte Betrachtung des gesamten Produktbestandes.
Der Einsatzzweck von Produktdaten-Clustern ist auch mannigfaltig. Als ein Beispiel sei die Erstellung einer Navigation für einen Onlineshop erwähnt. Hat man klare Produktcluster erstellt, können diese als Unterstützung oder Startpunkt bei der Erstellung einer nachhaltige, sinnhaften Produkt-Baum-Navigation dienen.
Erkennung von Falschbuchungen
Als drittes Beispiel nutzen wir die Erkennung von Ausreißern mittels Clustering. Bei großen Unternehmen gibt es hunderte bis tausende Buchungen jeden Tag. Durch die Definition von Clustern werden Standard-Buchungen in Gruppen gefasst. Wenn dabei Buchungen identifiziert werden, die weit von allen Gruppen entfernt sind, können diese als Ausreißer definiert werden.
Als nachfolgenden Schritt gilt es, diesen Ausreißern nachzugehen. Da jedoch die Quantität durch das Clustering massiv reduziert wurde, ist es auch durch wenige Mitarbeiter abzudecken und somit sehr effizient zu arbeiten.
Unsere KI-Produkte basierend auf Clustering


Was ist Kobold AI?
Kobold AI bietet den Einsatz künstlicher Intelligenz ohne technisches Vorwissen. Einfach, schnell und günstig KI anwenden, um Mehrwert durch Daten zu generieren.
Wie es funktioniert erklärt unser interaktives Video: