

Datenqualitätsanalyse von Kundendaten
299,00 €
Analyse von Kundendaten im Bezug auf Datenqualität wie Vollständigkeit, Validität, Korrektheit und anderes.
Beschreibung
Diese Daten brauchen wir
- Inhalt: Ein Kundendatensatz
- Quellen: Beliebiges System, z.B. CRM, Business Intelligence oder Excel-Listen
- Format: Eine Reihe ein Kunde, beliebige Anzahl an Spalten
Kundendaten sind zentral für jedes Unternehmen. Alle Prozesse greifen früher oder später darauf zurück. Doch oft lässt die Qualität dieser Daten zu wünschen übrig. Dieses Produkt analysiert die Datenqualität von Kundendaten und gibt Empfehlungen, wie man sie verbessern kann.
Datenqualitätsanalyse bei Kundendaten – Informationsvideo
Warum ist Datenqualität bei Kundendaten wichtig?
Die Daten von Kunden begleiten jedes Unternehmen von der ersten Stunde. Anfangs meist noch sehr grundlegend zur Bestellabwicklung, gibt es bald eine ganze Bandbreite an gespeicherten Informationen.
Im Kundenservice, der Logistik, den digitalen Kanälen wie dem E-Commerce-Shop oder einfach einer Newsletteranmeldung werden Kundendaten erfasst oder abgerufen. Und im Optimalfall angereichert: Wie ist das Bestellverhalten, werden Dinge reklamiert, welche Probleme haben diese Kunden und wie interessiert sind sie am Content?
Klar ersichtlich ist, dass es sehr wichtig ist, dass die Kundendaten von hoher Qualität sind. Kontaktdaten müssen stimmen um nachzufassen, Verhaltensdaten um Kunden besser zu verstehen und die Querverbindung zwischen den verschiedenen Systemen erlaubt einen 360° Blick auf das Profil.
Dabei geht es vor allem um eine Effizienz von Prozessen (z.B. richtige Lieferungen, Rechnungen), aber auch ein optimales Kundenerlebnis (z.B. Übertrag von Information zwischen Systemen, schnelle Abwicklung von Service-Einsätzen). Zusammen bilden verlässliche Kundendaten die Basis für ein gutes Kundenerlebnis und einen nachhaltigen Einsatz im Unternehmen.
Ursachen von geringer Datenqualität
Doch wie kommt eine niedrige Datenqualität bei Daten zu Stande? Es gibt eine Bandbreite an Gründen, die meist auch interagieren:
Legacy-Daten aus Legacy-Systemen
Stammdaten wie Kundendaten oder Produktdaten sind meist einer der ersten Datensätze in jedem Unternehmen. Und da sie zentral für die Kundenbetreuung, Produktentwicklung und Verkäufe sind, werden sie auch meist mit in neue Systeme migriert. Die Konsequenz sind veraltete Formate, fehlende Felder, falsche Datentypen und vieles mehr.
Der Faktor Mensch
Stammdatensystem werden meist durch Menschen befüllt. Egal ob von extern (z.B. Kunden) oder einem internen Mitarbeiter (z.B. Produktdaten): Menschen machen Fehler. Und diese Fehler spiegeln sich in der niedrigen Datenqualität wieder.
Fehlendes Bewusstsein
Meistens ist das Hauptproblem, dass nicht klar ist, wie wichtig Daten überhaupt sind. Ob für Kundenservice oder Datenanalysen: Sie brauchen gute, saubere Daten. Doch selten wird Data Governance als zentral für ein Unternehmen gesehen, weshalb schlechte Datenqualität selten korrigiert wird.
Ziel einer Ad-Hoc Datenqualitätsanalyse
Doch wie geht man die Korrektur schlechter Daten an? Als erstes empfiehlt sich, die Datenqualität umfassend zu überprüfen. Oft ist unklar, wie schlecht die Qualität wirklich ist und woran es genau fehlt. Es ist eine „gefühlte“ Datenqualität, die aber kaum belegt ist.
Hier kommen Datenqualitätsanalysen ins Spiel. Eine dedizierte Ad-Hoc Analyse der Datenqualität erlaubt es, genau festzustellen, welche Ansatzpunkte zur Verbesserung es gibt.
Egal ob als Data Scientist vor einer Analyse oder Berater vor einer CRM-Umstellung: Sich klar zu sein, welchen Zustand die Daten haben, ist fundamental. Doch dies ist oft mit hohem (manuellen) Aufwand verbunden. Deshalb haben wir ein Produkt entwickelt, das die Datenqualitätsanalyse automatisiert durchführt.
Automatische Datenqualitätsanalyse mit Kobold AI: Vorgehen und Ergebnis
Unsere automatisierte Datenqualitätsanalyse untersucht mehrere Faktoren von schlechter Datenqualität. Alle haben gemein, dass sie Hinweise darauf geben, welche Qualität die einzelnen Attribute haben und ob der nächste Schritt – die Korrektur – sinnvoll ist. Folgende Analysen führen wir durch:
Initiale Datenanalyse: Einfache Statistik als Überblick
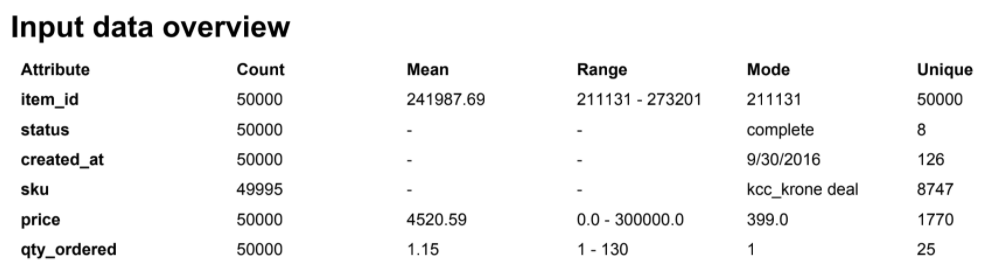
Als gutes erste Indiz für schlechte Qualität ist die Untersuchung der Attribute auf Inhalt. Dazu führen wir eine initiale Datenanalyse durch. Anzahl an Werten, deren Durchschnitt (Mean / Median), die Spannweite (Range) und wie viele einzigartige Werte sich darin befinden. Bereits diese einfache Analyse kann Hinweise geben, wenn ein Attribut anders befüllt ist als erwartet (z.B. falsche Spannweite durch Ausreißer, mehr einzigartige Werte als erwartet).
Datenvollständigkeit: Klare Interpretation ermöglichen
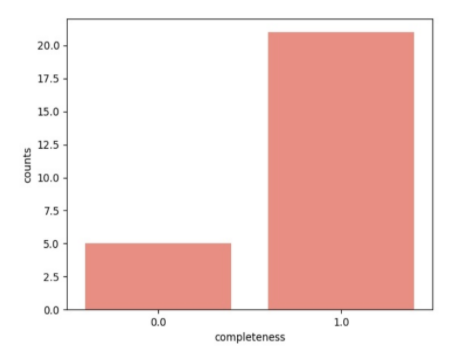
Das nächste Datenqualitätsattribut ist die Vollständigkeit jeder Spalte. Hierzu werden leere Felder gezählt und prozentual auf die Gesamtanzahl umgelegt. Generell sollte die Completeness in einem hoch qualitativen Datensatz bei 100% liegen, so dass keine leeren Felder auftreten. Doch muss hier Vorwissen zu den Daten eingesetzt werden, da gewisse Attribute teilgefüllt sinnvoll sein können (z.B. “Doktortitel”).
Da leere Felder schwierig zu interpretieren sind (Keine Angabe? Fehlende Angabe? Fehler im Übertrag?), sollten sie für eine hohe Datenqualität mit Platzhaltern gefüllt werden (z.B. “NA”, “no value”, “0”).
Data Validity: Zur Überprüfung von Datentypen

Die nächste wichtige Metrik sind Datentypen. Wenn ein Attribut zum Beispiel numerischen Inhalt beinhalten soll, aber auch Text aufweist, ist das ein Indiz für schlechte Datenqualität.
Daher prüfen wir die Data Validity, also die Verteilung von leeren, Text und numerischen Inhalten für jedes Attribut. Widerspricht ein Eintrag der Erwartung, muss dem nachgegangen und die fehlerhaften Werte korrigiert werden.
Dubletten: Doppelte Einträge identifizieren

Data Sparseness, also die Datensparsamkeit ist ein weiteres Attribut von hoher Datenqualität. Im Falle von Duplikaten bzw. Dubletten hat dies auch klare Kosten- und Kundennutzen. Wenn zum Beispiel ein Kunde mehrfach erfasst ist, kann es sein, dass es Probleme in der Lieferabwicklung und Rechnungsstellung gibt. Oder der Kunde wird mehrfach mit Marketingmaterial überhäuft.
Daher prüfen wir für jeden Eintrag im Datensatz, ob ein Duplikat existiert. Da es relativ selten ist, dass es exakte Duplikate gibt, gehen wir einen Schritt weiter und untersuchen auch die Duplikate bei Ausschluss eines Attributs. Folglich können auch “verdeckte” Dubletten erkannt und korrigiert werden.
Doppelte Attribute: Datensparsamkeit fördern
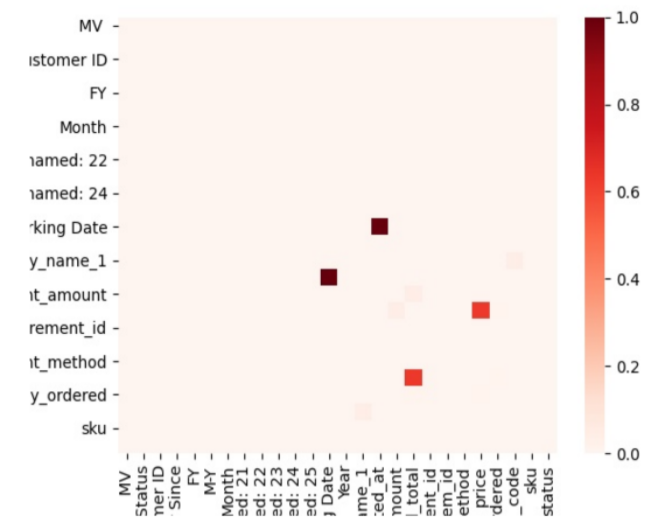
Doppelte Einträge sind ein Problem für Prozesse, doppelte Attribute hingegen für Systeme und Datenhaltung. In dieser Analyse stellen wir fest, ob es für Spalten im Datensatz identische Inhalte gibt.
Datenredundanz: Ähnliche Attribute evaluieren
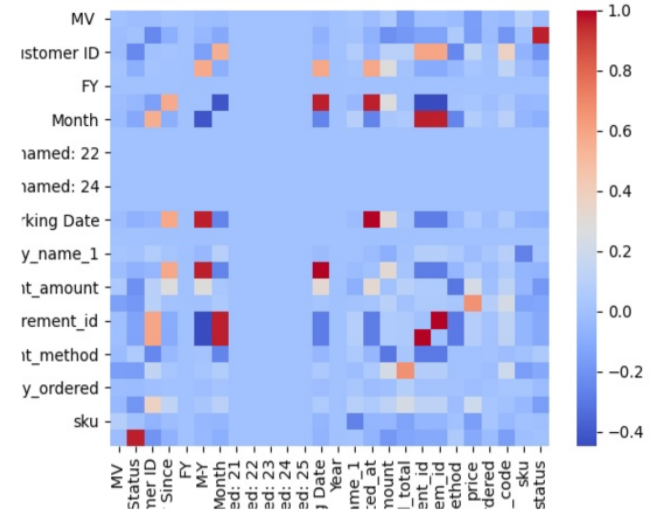
Während die doppelte Spaltenerkennung nur identische Werte findet, gehen wir in der Datenredundanz-Analyse weiter und untersuchen die Kundendaten auf Spalten, die sehr stark miteinander korrelieren, also die gleichen Werte ausweisen.
Der Unterschied zu doppelten Spalten ist, dass der Inhalt nicht identisch sein muss, aber zwei Werte immer gleichzeitig auftreten, was eine Redundanz darstellt (zum Beispiel Gewicht in Kilogramm und Gewicht in Gramm).
Datengenauigkeit: Ausreißer erkennen

Aufbauend auf initiale Analyse untersuchen wir in der Data Accuracy ob die realen Werte unserer Erwartung entsprechen. Vor allem im Bezug auf Werteverteilungen, Ausreißerhäufigkeiten und Beispielen untersuchen wir die Qualität.
Findet man beispielsweise unerwartet hohe Werteverteilungen (zum Beispiel Warenkorbwert im E-Commerce) oder viele Ausreißer, muss man sich Gedanken über die Herkunft und ggf. Auswirkung auf Reporting und Finanzen machen.
Datengenauigkeit: Länge als Inhaltsqualität

Abschließend nutzen wir noch die Zeichenlänge jedes Attributs, um zu untersuchen, ob die Werte unserer Erwartung entsprechen. Vor allem bei standardisierten Daten sollte eine Abweichung Alarmglocken anwerfen. Ein 20-stelliger Preis? Eine ISBN die nicht 13 Stellen lang ist? Ein Vornamen-Feld mit nur einem Zeichen?
Schnell erkennt man, wie einfach nur die erwartete Spannweite und durchschnittliche Länge eines Attributs ein klarer Hinweise auf schlechte Kundendatenqualität sein kann.
Self-Service KI mit Kobold AI: Wie es funktioniert
Kobold AI ist eine Self-Service Plattform für KI-Produkte. Das heißt, jeder Besucher kann unsere standardisierten KI-Produkte wie die Datenqualitätsanalyse einfach und ohne Hürden bestellen. Es werden eigene Daten bereitgestellt, durch diese eine individuelle Analyse erfolgt und direkt im Postfach des Kunden landet.
Wie funktioniert Self-Service KI mit Kobold AI?
Kobold AI macht künstliche Intelligenz zugänglich für Nicht-Experten. Auf unserer Online-Plattform werden KI-Produkte und deren Mehrwert erklärt und können einfach durch einen Klick bestellt werden. Durch die Bereitstellung der eigenen Daten werden automatisiert individuelle Ergebnisse geliefert.
Der Vorteil zu anderen Vorgehensweisen im Bereich künstliche Intelligenz ist kein Aufwand für Integration, kein notwendiges Datenexperten-Wissen und eine schnelle, günstige Abwicklung. Einfach bestellen, Ergebnisse bekommen.
Erwartete Eingabe
- Spalten: Beliebige Anzahl von Attributen
- Zeilen (max. 50.000): Eine pro Entität (Kunde/Partner/Nutzer/Produkt/Einsatz,..)
Beispiel für eine Datenqualitätsanalyse
Beispielbericht für die Analyse von Datenqualität herunterladen
Der nächste Schritt: Erhöhung der Datenqualität
Hat man die Datenqualität seiner Daten analysiert, bleibt selbstverständlich der nächste Schritt: Die Interpretation und anschließende Verbesserung der Daten. Hierzu sehen wir drei generelle Ansatzpunkte:
- Awareness schaffen: Die Datenqualitätsanalyse erlaubt es, im eigenen Unternehmen klar zu machen, weshalb es ein Problem mit der Datenqualität gibt. Folglich kann man damit Buy-In einholen, sich um die Verbesserung zu kümmern.
- Monitoring: Ein automatisches Monitoring oder eine regelmäßige Datenqualitätsanalyse erlaubt es, kontinuierlich informiert zu sein falls sich die Qualität verschlechtert. Somit weiß man früh, welche Probleme sich ergeben.
- Prozesse: Am wichtigsten ist die Einführung von datenqualitätserhöhenden Prozessen. Sei es durch Software wie beschränkte Eingabefelder (z.B. Dropdown statt Freitext) oder klare Richtlinien was bei leeren Feldern hinterlegt werden soll / muss; beides erlaubt ein “First time right” – also eine korrekte Eingabe – zu gewährleisten.
Zusammenfassung einer Kundendatenqualitätsanalyse
Die Analyse von der Qualität von Kundendaten hilft in vielen Situationen. Ob sporadisch, um ein existierendes CRM zu überprüfen, bei einer Migration von Daten oder um menschliche Awareness zu schaffen – es gibt viele Gründe, weshalb es wichtig ist, Transparenz über den Status Quo der Datenqualität zu haben. Die Korrektur der falschen Daten und Verhinderung erneuter Verschlechterung sind dann die nachfolgenden Aufgaben, die es Unternehmen erlauben, eine kontinuierlich hohe Qualität vorweisen zu können.
Du musst angemeldet sein, um eine Rezension veröffentlichen zu können.
Ähnliche Produkte
-

Analyse von verlorenen Wiederkäufern
349,00 € -
Coming soon

Warenkorb Analyse für E-Commerce
149,00 € -

Personenbezogene Daten identifizieren
399,00 € -

Analyse von Onsite-Search im E-Commerce
499,00 € -

Vorhersage von Angebotsannahme (B2B, B2C)
399,00 € -
Coming soon

Vorausschauende Wartung für Maschinen
399,00 €
Rezensionen
Es gibt noch keine Rezensionen.