
Kundenabwanderung: Analyse und Vorhersage
499,00 €
Die KI-basierte Vorhersage von Kundenabwanderung führt zu klarer Ressourcenfokussierung zu höherer Loyalität und somit höheren Umsatz.
Beschreibung
Die Analyse und Vorhersage von Kundenabwanderung durch künstliche Intelligenz erlaubt es, effizient und gezielt die Kundenbindung zu erhöhen und somit Umsatz zu erhalten.
Das Wichtigste in Kürze
Diese Daten brauchen wir
- Inhalt: Kunden-Stammdaten, Transaktionsdaten, Verhaltensdaten
- Quellen: CRM, ERP, E-Commerce, Excel
- Format: Eine Reihe = ein Kunde, beliebig viele Spalten; Eine Spalte „target“ mit „1“ für historische Abwanderung, „0“ für Nicht-Abwanderung, ein leeres Feld für die Vorhersagezeilen
Inhaltsverzeichnis
Kundenbindung ist die bessere Kundenakquise
Kundenbindung ist eine der wirksamsten Methoden, um einem Unternehmen kontinuierliche Einnahmen zu sichern. Dennoch ist es oft schwer zu verstehen, warum Kunden nicht zurückkehren um zu kaufen oder sogar vorhandene Verträge kündigen. Und aufgrund begrenzter Ressourcen ist es unmöglich, sich um alle Kunden zu kümmern und sie persönlich zu kontaktieren.
Daher besteht einer der Ansätze in datengesteuerten Unternehmen darin, herauszufinden, welche Kunden als nächstes abwandern könnten, und diesen eine persönliche Betreuung zukommen zu lassen. Die Idee hinter einer solchen Priorisierung ist, die Kapazitäten auf die Kunden zu konzentrieren, die am ehesten abwandern werden. Die nachfolgenden Maßnahmen können personalisierte E-Mails, Schulungsangebote, Gutscheine oder spezielle Verträge sein.
Die Vorhersage der Kundenabwanderung ist somit eine Möglichkeit, einerseits die Kundenzufriedenheit zu erhöhen, andererseits aber auch die Kundenbindung zu verbessern.
Welchen Wert hat die Vorhersage der Kundenabwanderung?
Wie bereits angedeutet, ist das Wissen darüber, welche Kunden wahrscheinlich einen Vertrag kündigen oder nicht wieder kaufen werden, nur der Anfang. Aber schon in diesem Stadium ist es gut zu wissen, wie viele Kunden zurückkehren werden und wie viel Umsatz dementsprechend in den folgenden Monaten zu erwarten ist.
Noch interessanter wird die Idee natürlich, wenn Folgeaktionen geplant werden. Wenn ein Unternehmen weiß, welche Kunden abwandern werden, kann es die Kunden mit dem höchsten Wert (z. B. auf der Grundlage der Vertragsgröße oder des Multiplikationswerts) auswählen und geeignete Gegenmaßnahmen ergreifen.
Diese Gegenmaßnahmen können von einer einfachen Kundenbindungs-E-Mail über personalisierte Gutscheine bis hin zu Anrufen eines Vertriebsmitarbeiters reichen, der versucht, den Kunden zu halten.
In jedem Fall kann ein Unternehmen, wenn es a) den Wert der zu verlierenden Einnahmen ermittelt und b) für jeden einzelnen Kunden weiß, wie hoch die Wahrscheinlichkeit ist, dass er abwandert, das Verhältnis zwischen Akquisition und Bindung optimieren und die Kapazitäten dort einsetzen, wo sie benötigt werden.
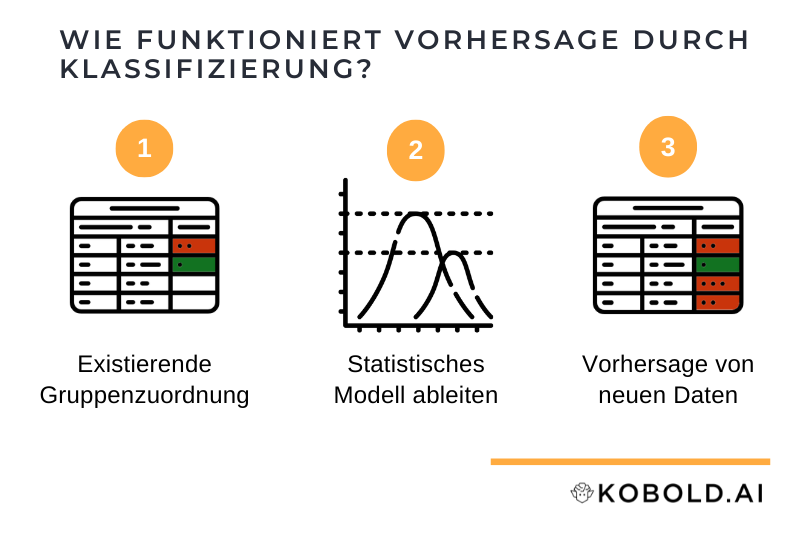
Wie funktioniert eine Vorhersage durch Klassifizierung?
Die Klassifizierung von Daten ist eine der klassischen Aufgaben von künstlicher Intelligenz, genauer von Machine Learning. Dazu werden vorhandene Datensätze und deren Gruppenzuordnung genutzt, um ein allgemeines Modell der Zuordnung abzuleiten. Dieses Modell kann dann zur Vorhersage für noch unbekannte Daten genutzt werden.
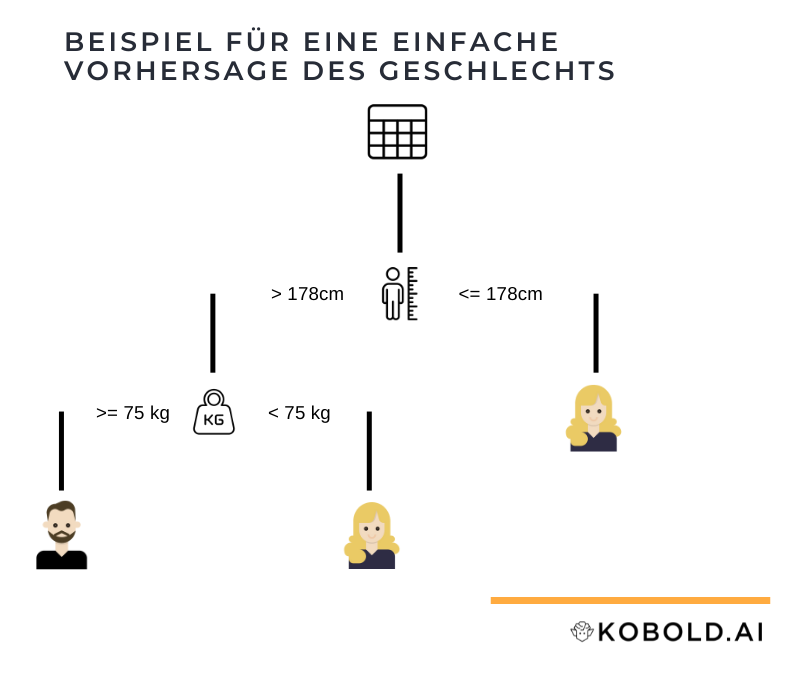
Ein einfaches Beispiel: Nehmen wir an, wir möchten vorhersagen, um welches Geschlecht (männlich, weiblich) es sich bei vorliegenden Daten (Größe, Gewicht, Alter) handelt.
Im ersten Schritt benötigen wir ein sogenanntes Trainingsset. Das sind Daten, die die Attribute (Größe, Gewicht, Alter) und die Kategorie (männlich, weiblich) beinhalten. Also reale Beispiele von korrekter Klassifizierung.
Diese Daten werden im zweiten Schritt mittels maschinellem Lernen generalisiert. Anhand der Beispiele wird ein statistisches Modell generiert, das festlegt, bei welche Art von Daten welche Kategorie die wahrscheinlichste ist.
Als letztes kann dieses Modell eingesetzt werden um anhand neuer Daten (Größe, Gewicht, Alter) die Kategorie vorherzusagen.
Das gleiche Prinzip wie in dem Beispiel findet sich auch in diesem Anwendungsfall wieder. Nur mit mehr Daten und etwas mehr Komplexität.
Welche Art von Daten wird für die Vorhersage der Kundenabwanderung verwendet?
Die Kundenabwanderung lässt sich am besten vorhersagen, wenn die Daten die Gründe aufzeichnen, aus denen ein Kunde ein Unternehmen verlässt. Je mehr Daten also die tatsächlichen Gründe („Kausalität“) für einen unzufriedenen Kunden widerspiegeln, desto besser. Hier ein Überblick über die am häufigsten verwendeten Datenquellen:
- Customer Relationship Management System (CRM) für relevante kundenbezogene Stammdaten (z.B. Demographie für B2C oder Unternehmensgröße für B2B)
- ERP- oder E-Commerce-System für Transaktionsdaten (z.B. durchschnittliche Warenkorbgröße, kategoriale Präferenzen, Bestellhäufigkeit)
- Servicedatensystem für einen Zufriedenheitsindex (z. B. Häufigkeit und Art der Kontakte)
- Produkt- oder Stammdatenverwaltungssystem für Informationen über Verträge und / oder Produkte, die vom Kunden genutzt werden
- Interne Logging-/Analysesysteme für Verhaltensdaten (z. B. Anzahl der Logins, Interaktionen mit der Plattform, Verweildauer auf der Seite, Nutzeraktivitäten)
Erwartetes Datenformat für eine Klassifizierung
Das Datenformat für eine erfolgreiche Klassifizierung ist tabellarisch. Es wird eine beliebige Anzahl an Attributen als Spalten erwartet (zum Beispiel Größe, Gewicht, Alter,..). Die letzte Spalte mit dem Namen “target” beinhaltet dann entweder eine 0 für die eine Gruppe (z.B. weiblich), eine 1 für die andere Gruppe (z.B. männlich) oder keinen Wert (wird durch das Modell vorhergesagt).
Jede Zeile hingegen repräsentiert einen Fall der bekannten Gruppen (0 und 1) oder bisher noch unbekannten Gruppe (leerer Wert) aber mit allen notwendigen Attributen. Zusammengefasst sieht ein beispielhafter Datensatz für eine Klassifizierung aus wie folgt:
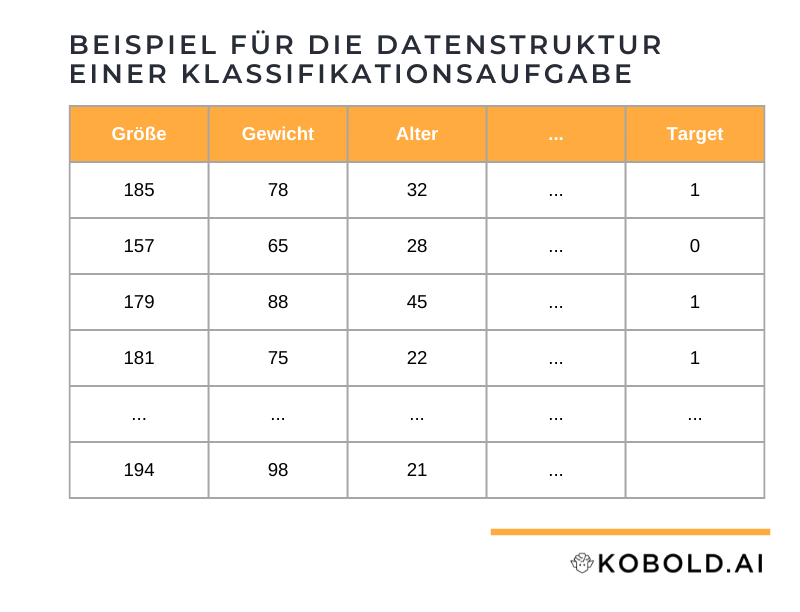
Zusammengefasst:
- Beliebig viele Spalten mit Attributen die die Gruppen beschreiben
- Die letzte Spalte mit Namen “target” mit 0 für eine Gruppe, 1 für die andere; ein leerer Wert für zu klassifizierende Werte
- Jede Zeile ist ein Datensatz
Bitte vermeiden Sie leere Datenfelder, Spalten mit sehr hoher Varianz (z.B. gruppieren Sie „Wohnort“ in Land statt adressbasiert) und entfernen Sie alle Personen identifizierenden Informationen (GDPR-Relevanz).
Ein praktisches Beispiel wie eine Input-Datei aussehen kann, finden Sie hier: Beispiel-Datei ansehen
Wie funktioniert Self-Service KI mit Kobold AI?
Kobold AI macht künstliche Intelligenz zugänglich für Nicht-Experten. Auf unserer Online-Plattform werden KI-Produkte und deren Mehrwert erklärt und können einfach durch einen Klick bestellt werden. Durch die Bereitstellung der eigenen Daten werden automatisiert individuelle Ergebnisse geliefert.
Output des Produkts – Lieferobjekte und Inhalte
Sie erhalten eine detaillierte Analyse von
- Deskriptive Analysen der Eingabedaten, z.B. ob es Attribute gibt, die eine hohe Korrelation mit der Konversion haben
- Ein Vorhersagemodell und die dazu beitragenden Faktoren
- Die Vorhersage für alle hinzugefügten Leads, ob sie konvertieren werden oder nicht
Beispiel
Ein Beispiel für den Output eines Klassifizierungs- / Vorhersageprodukts ist:
Häufige Fragen zur Klassifizierung von Gruppen (FAQ)
Ist die Vorhersage zu 100% korrekt?
Nein! Das Klassifizierungsmodell beruht auf statistischen Wahrscheinlichkeiten und hat somit eine Unschärfe. Wie viel Prozent der Fälle korrekt vorhergesagt werden, ist im Output ersichtlich. Dabei gilt üblicherweise: Umso mehr Beispiele und umso mehr sinnvoll beschreibende Daten, umso besser das Ergebnis.
Welchen Algorithmus nutzt ihr in der Klassifizierung?
Das ist natürlich ein gewisses Geheimnis, da wir eine vollautomatische Datenverarbeitung einsetzen. Aber es sei gesagt, dass wir uns nicht auf einen einzigen Algorithmus in nur einer Konfiguration stützen, sondern eine Vielzahl an Algorithmen testen um das beste Ergebnis zu liefern.
Wie viele Gruppen kann ich klassifizieren lassen?
Momentan arbeiten wir mit binären Klassifizierungen, die zwischen zwei Gruppen unterscheiden können. In der Zukunft werden wir auch mehrere Gruppen ermöglichen.
Ist die Anzahl an Daten wichtig?
Ja, umso mehr Daten, speziell bereits Gruppen zugeordnete, umso besser das Training und somit die Vorhersage.
Was sind Trainingsdaten?
Die gelieferten und mit Label (target 0, 1) versehenen Daten sind die Trainingsdaten, mit denen das Modell trainiert wird.
Wie viele Attribute soll ich liefern?
Die Frage sollte eher lauten: Welche! Denn am besten genau diese, die sinnvoll eine beschreibende Funktion für die Vorhersage liefern. Umso mehr es am Ende sind, umso besser, denn jedes Attribut sollte beschreibende Information beinhalten.
Dabei gilt: Nur komplette Daten ohne Fehlwerte machen Sinn.
Wie viele Attribute kann ich liefern?
Prinzipiell beliebig viele. Doch sortiert unser Algorithmus automatisch redundante, hochkorrellierende oder nichts-sagende Attribute aus. Daher lieber einen sinnvollen Umfang, der dann auch in der Praxis einsetzt werden kann, also alles was möglich ist.
Zusammenfassung: Wie die Vorhersage von Kundenabwanderung Mehrwert stiftet
Die Möglichkeit, durch künstliche Intelligenz Kundenabwanderung vorherzusagen eröffnet neue Perspektiven im Bezug auf Kundenbindung. Ganz gezielt können die Kunden identifiziert und kontaktiert werden, die in Gefahr laufen abzuwandern. Ob Kündigung oder kein Wiederkauf: Sowohl Abo-Modell als auch E-Commerce kann von einer Kundenabwanderungsvorhersage profitieren.
Neben der absoluten Vorhersage ist aber vor allem auch die Vorabanalyse durch Kobold AI zentral: Ein besseres Verständnis, weshalb Kunden abwandern, erlaubt es die eigene Strategie anzupassen, besseren Service zu bieten oder einfach schneller zu reagieren. KI zur Vorhersage von Kundenabwanderung mit Kobold AI: Zentral für eine effiziente Kundenbindungsrate.
Du musst angemeldet sein, um eine Rezension veröffentlichen zu können.






Rezensionen
Es gibt noch keine Rezensionen.