
Vorhersage von Lead-Konvertierung
399,00 €
Leads zu qualifizieren basiert oft auf qualitativen Meinungen oder Scoring-Modellen. Wir nutzen KI, um anhand historischer Konvertierung zukünftige Wahrscheinlichkeiten vorherzusagen.
Beschreibung
Die Vorhersage von Lead Konvertierung hat zum Ziel, selektiv die potentiellen Kunden zu kontaktieren, bei denen die höchste Wahrscheinlichkeit für eine Konversion besteht. Mit Hilfe von künstlicher Intelligenz kann dieses Vorgehen automatisiert und optimiert werden.
Das Wichtigste in Kürze
Diese Daten brauchen wir
- Inhalt: Stammdaten, Verhaltensdaten, Transaktionsdaten
- Quellen: CRM, ERP, e-Commerce, Newsletter
- Format: Eine Reihe = ein Lead, beliebig viele Spalten; Letzte Spalte „Target“ mit 0 für Nicht-konvertiert, 1 für konvertiert, leer für Vorhersagen
Inhaltsverzeichnis
Wofür braucht man eine Vorhersage von Lead-Konvertierung?
Viele Unternehmen haben mehr Leads als sie sinnvoll verarbeiten können. Vor allem im digitalen Bereich mit den vielen möglichen Kanälen ist es einfach, Kontakte und mögliche Kunden zu sammeln.
Doch der Follow-Up bindet Ressourcen. Wenig SDRs die sich auf schlecht qualifizierte Leads stürzen heißt im Umkehrschluss oft eine sehr niedrige Erfolgsquote. Also ist es am besten, wenn man vorab weiß, welche Leads eine hohe Wahrscheinlichkeit zur Konvertierung haben.
Hier kommt künstliche Intelligenz ins Spiel. Durch den Einsatz von Machine Learning kann man aus alten Lead-Vorgängen lernen um für neue Leads vorherzusagen, ob sie konvertieren werden oder nicht.
Die Vorteile liegen auf der Hand:
- Klare Fokussierung von verfügbaren Ressourcen
- Höhere Chance, Verträge abzuschließen
- Besseres Territory-Planning und Priorisierung von Inbound leads
- Verständnis, welche Faktoren zu einem positiven Abschluss beitragen
Damit diese Vorhersagen erstellt werden können, werden Daten von alten Leads eingesetzt um ein Klassifizierungsmodell (konvertiert / nicht konvertiert) zu trainieren. Dieses Modell wird dann auf neue Leads angewandt – und somit eine Vorhersage generiert, ob es wahrscheinlich ist, dass sie konvertieren.
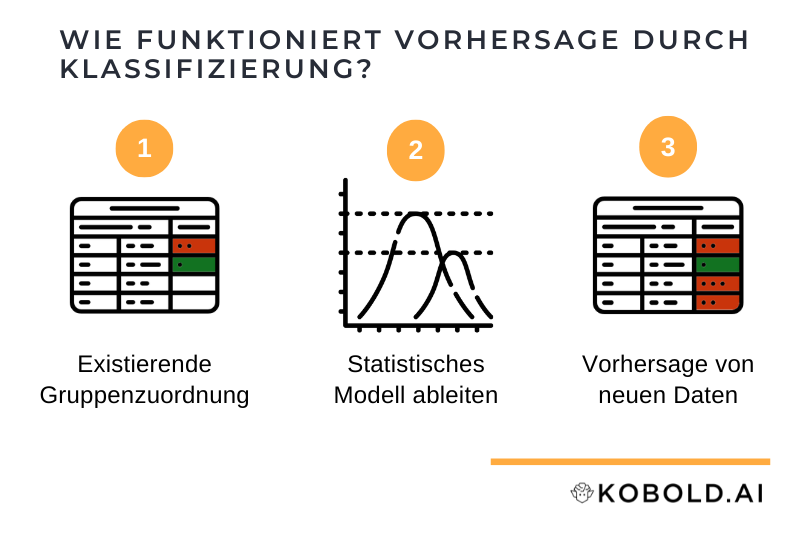
Wie funktioniert eine Vorhersage durch Klassifizierung?
Die Klassifizierung von Daten ist eine der klassischen Aufgaben von künstlicher Intelligenz, genauer von Machine Learning. Dazu werden vorhandene Datensätze und deren Gruppenzuordnung genutzt, um ein allgemeines Modell der Zuordnung abzuleiten. Dieses Modell kann dann zur Vorhersage für noch unbekannte Daten genutzt werden.
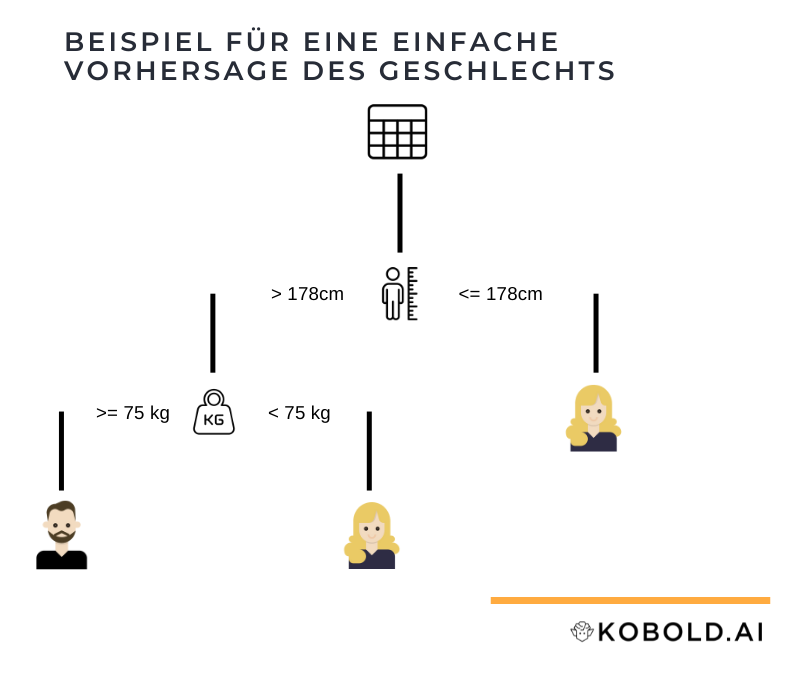
Ein einfaches Beispiel: Nehmen wir an, wir möchten vorhersagen, um welches Geschlecht (männlich, weiblich) es sich bei vorliegenden Daten (Größe, Gewicht, Alter) handelt.
Im ersten Schritt benötigen wir ein sogenanntes Trainingsset. Das sind Daten, die die Attribute (Größe, Gewicht, Alter) und die Kategorie (männlich, weiblich) beinhalten. Also reale Beispiele von korrekter Klassifizierung.
Diese Daten werden im zweiten Schritt mittels maschinellem Lernen generalisiert. Anhand der Beispiele wird ein statistisches Modell generiert, das festlegt, bei welche Art von Daten welche Kategorie die wahrscheinlichste ist.
Als letztes kann dieses Modell eingesetzt werden um anhand neuer Daten (Größe, Gewicht, Alter) die Kategorie vorherzusagen.
Das gleiche Prinzip wie in dem Beispiel findet sich auch in diesem Anwendungsfall wieder. Nur mit mehr Daten und etwas mehr Komplexität.
Datenquellen für Informationen zu Leads
Meistens weiß man relativ wenig über seine Leads, bevor man in den Sales-Prozess geht. Aber dennoch gibt es einige Datenquellen, die als Basis für eine gute Vorhersage dienen können:
- Unternehmensstammdaten: Industrie, Art, Größe, Umsatz und andere Eckpunkte sind meistens einfach zu besorgen oder selbst zu definieren
- Engagement: Welche Kanäle werden genutzt, welche Inhalte konsumiert, wie gelangt man an den Lead, wie viele Touchpoints gibt es – alles Möglichkeiten, die Intensität eines Kontakts zu beurteilen
- Qualitative Faktoren: Oft geht es unter, aber auch eine qualitative Beurteilung von bestehender Beziehung oder möglichem Erfolg kann in eine Vorhersage einfließen
Zusammen genommen gilt es zu überlegen, welche Daten zu Leads vorhanden sind oder akquiriert werden. Denn umso mehr Datenpunkte man hat, um mit umso mehr Indizien kann das Machine Learning Modell arbeiten.
Erwartetes Datenformat für eine Klassifizierung
Das Datenformat für eine erfolgreiche Klassifizierung ist tabellarisch. Es wird eine beliebige Anzahl an Attributen als Spalten erwartet (zum Beispiel Größe, Gewicht, Alter,..). Die letzte Spalte mit dem Namen “target” beinhaltet dann entweder eine 0 für die eine Gruppe (z.B. weiblich), eine 1 für die andere Gruppe (z.B. männlich) oder keinen Wert (wird durch das Modell vorhergesagt).
Jede Zeile hingegen repräsentiert einen Fall der bekannten Gruppen (0 und 1) oder bisher noch unbekannten Gruppe (leerer Wert) aber mit allen notwendigen Attributen. Zusammengefasst sieht ein beispielhafter Datensatz für eine Klassifizierung aus wie folgt:
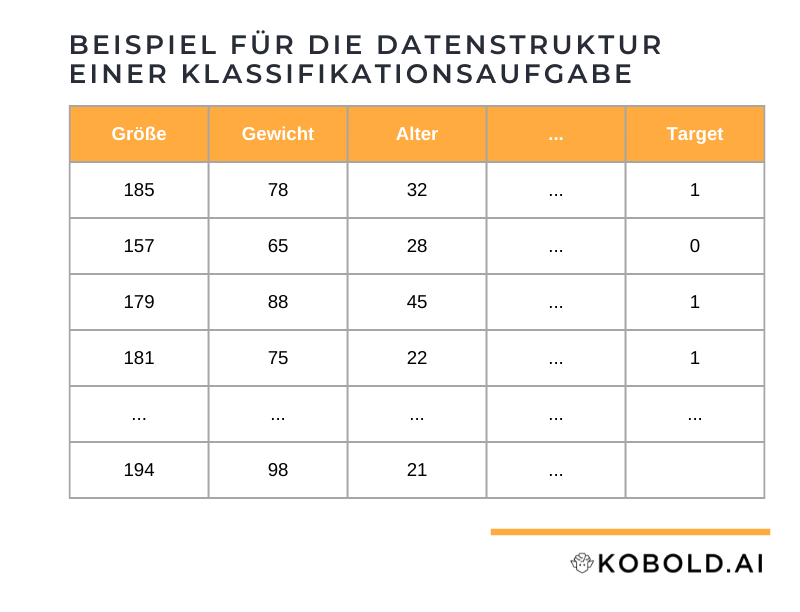
Zusammengefasst:
- Beliebig viele Spalten mit Attributen die die Gruppen beschreiben
- Die letzte Spalte mit Namen “target” mit 0 für eine Gruppe, 1 für die andere; ein leerer Wert für zu klassifizierende Werte
- Jede Zeile ist ein Datensatz
Bitte vermeiden Sie leere Datenfelder, Spalten mit sehr hoher Varianz (z.B. gruppieren Sie „Wohnort“ in Land statt adressbasiert) und entfernen Sie alle Personen identifizierenden Informationen (GDPR-Relevanz).
Ein praktisches Beispiel wie eine Input-Datei aussehen kann, finden Sie hier: Beispiel-Datei ansehen
Wie funktioniert Self-Service KI mit Kobold AI?
Kobold AI macht künstliche Intelligenz zugänglich für Nicht-Experten. Auf unserer Online-Plattform werden KI-Produkte und deren Mehrwert erklärt und können einfach durch einen Klick bestellt werden. Durch die Bereitstellung der eigenen Daten werden automatisiert individuelle Ergebnisse geliefert.
Output des Produkts – Lieferobjekte und Inhalte
Sie erhalten eine detaillierte Analyse von
- Deskriptive Analysen der Eingabedaten, z.B. ob es Attribute gibt, die eine hohe Korrelation mit der Konversion haben
- Ein Vorhersagemodell und die dazu beitragenden Faktoren
- Die Vorhersage für alle hinzugefügten Leads, ob sie konvertieren werden oder nicht
Beispiel
Ein Beispiel für den Output eines Klassifizierungs- / Vorhersageprodukts ist:
Häufige Fragen zur Klassifizierung von Gruppen (FAQ)
Ist die Vorhersage zu 100% korrekt?
Nein! Das Klassifizierungsmodell beruht auf statistischen Wahrscheinlichkeiten und hat somit eine Unschärfe. Wie viel Prozent der Fälle korrekt vorhergesagt werden, ist im Output ersichtlich. Dabei gilt üblicherweise: Umso mehr Beispiele und umso mehr sinnvoll beschreibende Daten, umso besser das Ergebnis.
Welchen Algorithmus nutzt ihr in der Klassifizierung?
Das ist natürlich ein gewisses Geheimnis, da wir eine vollautomatische Datenverarbeitung einsetzen. Aber es sei gesagt, dass wir uns nicht auf einen einzigen Algorithmus in nur einer Konfiguration stützen, sondern eine Vielzahl an Algorithmen testen um das beste Ergebnis zu liefern.
Wie viele Gruppen kann ich klassifizieren lassen?
Momentan arbeiten wir mit binären Klassifizierungen, die zwischen zwei Gruppen unterscheiden können. In der Zukunft werden wir auch mehrere Gruppen ermöglichen.
Ist die Anzahl an Daten wichtig?
Ja, umso mehr Daten, speziell bereits Gruppen zugeordnete, umso besser das Training und somit die Vorhersage.
Was sind Trainingsdaten?
Die gelieferten und mit Label (target 0, 1) versehenen Daten sind die Trainingsdaten, mit denen das Modell trainiert wird.
Wie viele Attribute soll ich liefern?
Die Frage sollte eher lauten: Welche! Denn am besten genau diese, die sinnvoll eine beschreibende Funktion für die Vorhersage liefern. Umso mehr es am Ende sind, umso besser, denn jedes Attribut sollte beschreibende Information beinhalten.
Dabei gilt: Nur komplette Daten ohne Fehlwerte machen Sinn.
Wie viele Attribute kann ich liefern?
Prinzipiell beliebig viele. Doch sortiert unser Algorithmus automatisch redundante, hochkorrellierende oder nichts-sagende Attribute aus. Daher lieber einen sinnvollen Umfang, der dann auch in der Praxis einsetzt werden kann, also alles was möglich ist.
Einsatz und Mehrwert der Vorhersage von Lead Konvertierung
Bleibt die finale Frage: Wie werden die Ergebnisse eingesetzt?
Wie beschrieben ist eines der größten Probleme in der Abhandlung von Leads die Priorisierung. Jedes Unternehmen hat begrenzte Ressourcen und prinzipiell unbegrenzte Möglichkeiten, Zeit zu investieren.
Mit der KI-basierten Vorhersage von Lead Konvertierung kann ein Unternehmen endlich effizient diese Ressourcen steuern. Ganz gezielt das Vertriebsteam auf Leads mit hohem Potential ansetzen ist für alle Unternehmen, von Startup bis Konzern, ein massiver Vorteil.
Aber nicht nur die operative Steuerung ist mit unserem KI-Produkt möglich. Durch die deskriptiven Analysen und auch Modellierung findet ihr auch heraus, welche Attribute wirklich wichtig sind für die Konvertierung. Folglich lassen sich auch strategische Initiativen ableiten, die sich nachhaltig auf eine höhere Qualität der Leads auswirkt.
Du musst angemeldet sein, um eine Rezension veröffentlichen zu können.






Rezensionen
Es gibt noch keine Rezensionen.