
Als Clustering, zu Deutsch “Clusteranalyse”, wird eine Kategorie von Algorithmen im maschinellen Lernen bezeichnet, die Daten in ähnliche Gruppen sortiert.
Der Vorteil von Clustering ist, dass die Methode als Unsupervised Machine Learning Algorithmus kein Vorwissen über die Daten benötigt und somit rein auf Ähnlichkeiten innerhalb der Daten operiert. Die Anwendung von Clusteringalgorithmen erfreut sich breiter Beliebtheit, von der Gruppierung von Kunden oder Produkten über die Ausreisserdetektion im Banking bis hin zur Nutzung als Spamfilter. In diesem Artikel starten wir mit einer Definition von Clustering, bevor wir die verschiedenen Methoden und Algorithmen vorstellen.
Inhaltsangabe
Definition von Clustering: Was ist das?
Einfach gesagt ist Clustering eine Methode im maschinellen Lernen, um Datenpunkte in Gruppen zu ordnen. Dabei werden Ähnlichkeiten der Daten (zum Beispiel ähnliches Alter, das gleiche Geschlecht) genutzt, um möglichst homogene Gruppen zu identifizieren (zum Beispiel junge, männliche Personen). Clustering arbeitet hierbei ohne vorhandenes Wissen, welche Einträge sich ähnlich sind, sondern berechnet die Ähnlichkeiten rein auf der Datengrundlage. Daher ist Clustering eine geeignete Methode um ohne Vorwissen Gruppen oder Segmente zu generieren und daraus Wissen abzuleiten.
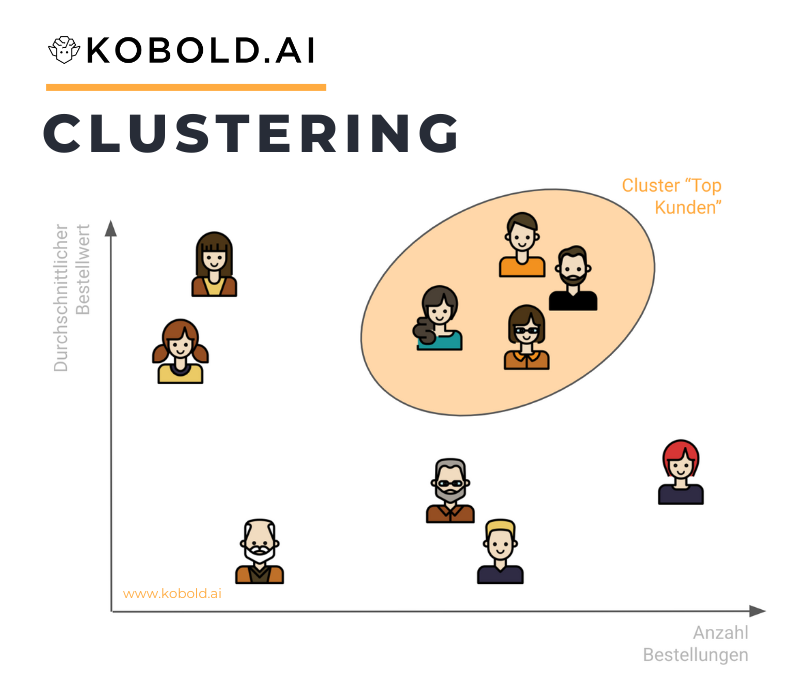
Die Ziele vom Einsatz von Clustering können grob in zwei Kategorien eingeordnet werden. Die erste Kategorie zielt darauf ab, ähnliche Datenpunkte zu kombinieren und somit Komplexität zu verringern. Die andere Kategorie versucht Datenpunkte zu identifizieren, die eben nicht zu einer großen Gruppe gehören und damit Besonderheiten aufweisen. Diese Kategorie nennt man Outlier-Detection, auf Deutsch Ausreissererkennung. In beiden Kategorien ist das Ziel ähnliche Gruppen zu identifizieren, um entsprechend angepasste Maßnahmen durchzuführen.
Dabei gibt es viele Themen bei denen dieser Erkenntnisgewinn Anwendung findet. Ob nun Kundenclustering, Produktclustering, als Fraud-Detection oder als Spamfilter – Clustering ist eine sehr versatile Herangehensweise im Bereich Machine Learning und Data Science.
Clustering als Methode im Unsupervised Machine Learning
Clustering als Methode gehört in den Bereich von Machine Learning, zu deutsch maschinellem Lernen. Hierbei ist es genauer als “Unsupervised Machine Learning”, also unüberwachtes Lernen klassifziert. Unsupervised Learning bedeutet, dass die Daten keine Zielvariable beinhalten, an denen sich der Algorithmus ausrichtet, sondern die Muster und Zusammengehörigkeiten rein auf den Daten selbst berechnet werden.
Da Clustering eine Methode im Machine Learning ist, fällt es auch in die Überkategorie Artificial Intelligence, zu Deutsch künstliche Intelligenz (KI). Algorithmen der künstlichen Intelligenz lernen anhand von Daten und können Muster oder Wissen ohne festgelegte Regeln extrahieren. Daher ist Clustering besonders interessant im Bereich Data Mining einzusetzen, um vorliegende Daten auf noch unbekannte Faktoren zu untersuchen.
Beispiele für den Einsatz von Clustering in Unternehmen
Kundengruppierung und Kundensegmente mittels Clustering
Ein sehr häufiges Anwendungsgebiet für Clustering ist der Einsatz im Marketing und der Produktentwicklung. Der Algorithmus wird hierbei genutzt, um sinnvolle Segmente ähnlicher Kunden zu identifizieren. Die Ähnlichkeit kann auf den Stammdaten (zum Beispiel Alter, Geschlecht), auf Transaktionsdaten (zum Beispiel Anzahl Einkäufe, Warenkorbwert) oder auch anderen Verhaltensdaten (zum Beispiel Anzahl Serviceanfragen, Dauer Mitgliedschaft im Loyaltyprogramm) basieren.
Hat man Kundencluster identifiziert, können individuellere Aktionen ausgerollt werden. Zum Beispiel ein personalisierter Newsletter, individuelle Angebote, verschiedene Arten von Serviceverträgen oder andere Aktionen sind die Folge von diesem besseren Kundenverständnis.
Clustering als Spamfilter
Ein weiteres interessantes Beispiel für Clustering im Einsatz im Alltag ist die Nutzung als Spamfilter. Hierbei werden Meta-Attribute von E-Mails (zum Beispiel Länge, Zeichenverteilung, Attribute über den Header..) eingesetzt, um Spam von realen E-Mails zu separieren.
Produktdatenanalyse: Gruppen, Qualität und mehr
Als anderes Beispiel für den Einsatz von Clustering im Unternehmen kann man die Nutzung von Clustering in der Produktdatenanalyse anführen. Produktdaten sind sehr zentrale Stammdaten in jedem Unternehmen und oft gelten sie als unter-gepflegt und unklar ob sie die beste Struktur aufweisen.
Clustering kann zum Beispiel helfen, Kategoriebäume und Produktdatenstrukturen zu entwickeln indem die Ähnlichkeit von Produktkategorien oder einzelnen Produkten anhand ihrer Stammdaten eingesetzt wird. Auch die Preisstrategie kann unterstützt werden, um zu sehen, welche Produkte faktisch sehr ähnlich sind und somit gegebenenfalls in den gleichen Preisbereich fallen.
Als zusätzliches Anwendungsgebiet im Produktdatenumfeld kann man die Produktdatenqualität anführen. Clustering kann helfen zu erkennen welche Produkte eine schlechte Datenqualität ausweisen und darauf basierend Empfehlungen für eine Korrektur geben.
Betrugserkennung mittels Clustering
Ein Beispiel von dem sowohl Konsument als auch die Unternehmen profitieren ist die Outlierdetection im Sinn einer Betrugserkennung. Banken und Kreditkartenunternehmen sind sehr aktiv in diesem Bereich und setzen (unter anderem) Clustering ein, um außergewöhnliche Transaktionen zu detektieren und zur Prüfung vorzumerken.
Welche Methoden und Algorithmen gibt es im Clustering?

Es gibt im Clustering wie in vielen anderen Bereichen des Machine Learnings inzwischen eine große Vielfalt an Methoden, die eingesetzt werden können. Je nach Anwendungsfall und vor allem Datenbasis kann dabei jeder Algorithmus ein anderes Ergebnis liefern. Dass dabei “anders” nicht immer besser oder schlechter ist, lasse ich bewusst offen. Denn Daten können auf viele Arten gruppiert und getrennt werden, vor allem wenn man von einem hochdimensionalen Raum spricht. Dies macht eigentlich erst die Komplexität von Clustering aus: den richtigen Algorithmus für den vorliegenden Anwendungsfall anzuwenden.
Im Folgenden möchten wir vier der prominentesten Clusteringalgorithmen vorstellen, bevor wir weitere Algorithmen zumindest stichpunktartig beschreiben.
k-Means als Beispiel für partitioning clustering
Partitioning clustering, auf Deutsch partitionierende Clusteranalyse, ist mitunter der bekannteste Clusteringalgorithmus. k-Means ist die dabei der am häufigsten genutzte Algorithmus in dieser Kategorie. Dabei steht das “K” für die Anzahl an zu definierenden Clustern, während “means” für den Mittelwert, also wo das Zentrum des Clusters steht.
Wie der Name somit bereits sagt, sucht sich k-Means für jeden ihrer Cluster einen Punkt, bei dem die Varianz zu allen umliegenden Punkten möglichst gering ist. Dies geschieht in einem iterativen Verfahren:
- Initialisierung: Zufällige Auswahl von K Zentren
- Zuweisung aller Datenpunkte zum nächstliegenden Zentrum, gemessen an einer Distanzmetrik
- Verschieben der Zentren in den Mittelpunkt aller zugeteilten Datenpunkte
- Gehe zu 2), ausser ein Abbruchkriterium ist erreicht
Dabei ist die Distanzmetrik der Abstand zwischen dem Datenpunkt und dem Cluster-Zentrum, wobei hier eine Bandbreite an Berechnungsmethoden eingesetzt werden kann (z.B. Euklidischer Abstand, Manhattan-Distanz). Zum Beispiel ist ein Mensch mit dem Alter 18 und der Körpergröße 160cm einem anderen Menschen mit dem Alter 20 und der Körpergröße 170cm näher als einem Menschen mit 60 Jahren und einer Größe von 190cm.
Ist der Algorithmus terminiert, hat also das Abbruchkriterium (z.B. Anzahl Durchgänge oder geringe Veränderung zum vorhergehenden Schritt) erreicht, gibt er für jeden Datenpunkt das Zentrum des am nähesten liegendsten Clusterzentrums aus.
Anwendungsgebiete und Besonderheiten von k-Means
Dass k-Means der am meisten genutzte Clustering-Algorithmus ist, geht auf seine Eigenschaften zurück. Einerseits ist er sehr einfach zu implementieren, andererseits skaliert er gut auch bei großen Datenmengen. Durch die Variation der Clustergröße kann man das Ergebnis gut iterativ steuern.
Die Nachteile bei k-Means sind, dass man die Clustergröße eben selbst festlegen muss, dass er sich primär für kreisförmige (sphärische) Cluster eignet und nur numerische Daten verarbeiten kann. Zusätzlich ist k-Means anfällig für Ausreisser, so dass ein Augenmerk auf das Preprocessing der Daten gelegt werden muss.
Was ist Kobold AI?
Kobold AI bietet den Einsatz künstlicher Intelligenz ohne technisches Vorwissen. Einfach, schnell und günstig KI anwenden, um Mehrwert durch Daten zu generieren.
Wie es funktioniert erklärt unser interaktives Video:
Hierarchisches (agglomeratives) Clustering
Neben k-Means ist hierarchisches Clustering einer der am häufigsten genutzten Algorithmen. Hierbei wird jedoch nicht vorab die Anzahl an Clustern definiert, sondern jeder Datenpunkt startet im eigenen Cluster und wird dann mit dem nähesten zusammengefasst. Grob sieht der Algorithmus folgendermaßen aus:
- Initialisierung: Jeder Datenpunkt ist ein Cluster
- Linkage: Für jeden Cluster wird der naheliegendste gemäß Distanzmetrik gefunden und diese Cluster zusammengeführt
- Gehe zu 2), außer ein Abbruchkriterium ist erreicht
Dabei ist der der relevante Teil offensichtlich die Linkage, also das Finden und Zusammenführen von zwei Clustern. Es gibt im Groben vier Arten von Linkage: Single Linkage, Average Linkage, Complete oder Maximum Linkage und Ward Linkage:
- Single Linkage, der einfachste Fall, nutzt die beiden einzelnen Datenpunkte innerhalb von zwei Clustern, die die geringste Distanz haben. Somit ist hierbei eine hohe Varianz “gut” für einen Cluster, da damit mehr andere Datenpunkte erreicht werden.
- Average Linkage vergleicht die Distanz von jedem Datenpunkt zu jedem anderen Datenpunkt eines anderen Clusters und nimmt dann deren Mittelwert. Folglich sind es nicht “Ausreisser” die bestimmen ob Cluster zusammengefügt werden, sondern die gesamte Komposition.
- Complete (Maximum) Linkage kehrt Single Linkage um und nimmt nicht die naheliegendsten Datenpunkte, sondern die am weitesten auseinander liegenden und wählt davon das Minimum zu den anderen Clustern. Folglich konzentriert es sich eher auf “Nicht-Ausreisser”.
- Ward Linkage nach Joe H. Ward, Jr. (1963) und vergleicht die Varianz von möglichen zusammengefügten Clustern. Als Varianzminimierungsverfahren ist es somit sehr ähnlich der k-Means Optimierung und versucht möglichst homogene Cluster zu formen.
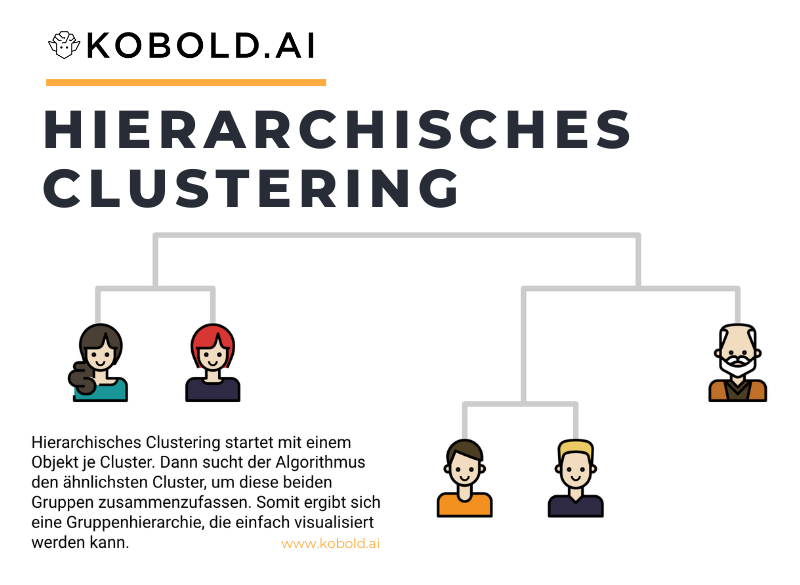
Anwendungsgebiete und Besonderheiten von hierarchischem Clustering
Hierarchisches Clustering hat die Besonderheit, dass man man genau die Zusammensetzung der Cluster bis auf Einzeldatenebene verfolgen kann. Dies macht die Methode besonders attraktiv in Gebieten, in denen man die Cluster in ihrer Zusammensetzung interpretieren möchte oder wenn vorab unklar ist, wie viele Cluster man festlegt.
Basierend auf diesen Gedanken machen alle Anwendungsfälle in denen die Nähe von einzelnen Datenpunkten interessant ist besonders mit hierarchischem Clustering Sinn. Zum Beispiel die Nähe von Personen oder Produkten kann sehr flexibel analysiert und in beliebig viele (oder wenige) Cluster formiert werden. Die daraus visualisierbaren Grafiken (“Dendogramm”) erlaubt es besonders visuell die Erkenntnisse zu vermitteln.
Schwierigkeiten hat hierarchisches agglomeratives Clustering hingegen durch die hohe Ressourcenanforderungen und Gruppierungseffekte die mehrere Cluster (unrechtmäßig) verbinden. Zum Beispiel kann durch Single-Linkage eine Art Brücke zwischen zwei Clustern geschlagen werden, die aber faktisch (noch) nicht zusammengehören, weil der Abstand zwischen den einzelnen Datenpunkten kleiner ist als die Dichte innerhalb der Cluster. Zuletzt ist es noch eine Herausforderung, zu bestimmten welche Anzahl an Clustern genau Sinn macht – hier sind sowohl Erfahrung als auch Domänenwissen gefragt.
DBSCAN (Density-Based Spatial Clustering of Applications with Noise)
Density-Based Spatial Clustering of Applications with Noise, auf Deutsch dichtebasierte räumliche Clusteranalyse mit Rauschen, ist ein Clusteringalgorithmus der vor allem im hochdimensionalen Raum oder zur Detektion von Ausreissern eingesetzt wird. Er basiert darauf, dass naheliegende Punkte zum gleichen Cluster gezählt werden, falls sie genug andere Punkte erreichen. Ist dies nicht der Fall, wird der Punkt als “Noise”, also Rauschen, definiert. Der High-Level Algorithmus funktioniert folgendermaßen:
- Für jeden Datenpunkt, stelle fest wie viele Datenpunkte nahe bei ihm liegen
- Wenn die somit zusammenhängenden Datenpunkte einen Grenzwert überschreiten, gilt es als Cluster mit Kernpunkten welche “dicht” sind
- Sind Datenpunkte von einem Kernpunkt erreichbar, aber erfüllen nicht den Grenzwert, gelten sie als dichte-erreichbar
- Sind Datenpunkte von keinem Kernpunkt erreichbar, gelten sie als Rauschen
Der Algorithmus wird durch zwei Parameter gesteuert: Die Länge des Grenzwerts (Epsilon, “Nachbarschaftslänge”) und die Mindestanzahl an Datenpunkten eines Clusters (minPoints). Erhöht man Epsilon, erlaubt dies für mehr Punkte im gleichen Cluster, man verliert allerdings Trennschärfe und legt ggf. mehrere Cluster zusammen. Erhöht man die Mindestanzahl, werden weniger Cluster erkannt und mehr Datenpunkte in Noise oder dichte-erreichbar eingeordnet.
Anwendungsgebiete und Besonderheiten von DBSCAN
DBSCAN hat einige Vorteile im Vergleich zu anderen Clusteringalgorithmen wie k-Means. Zum Beispiel kann DBSCAN Cluster jeder Form detektieren und differenzieren, nicht nur sphärische wie k-Means. Auch dass die Dichte der Cluster und nicht nur die Distanz mit einbezogen wird macht DBSCAN robuster gegenüber Ausreissern als andere Algorithmen.
Probleme hingegen sind, dass durch die beiden Parameter sehr stark die Verhaltensweise des Algorithmus gesteuert wird. Dies erfordert viel Erfahrung oder zumindest Experimentierfreudigkeit. Weiterhin kann DBSCAN nicht partitioniert werden, da zu jedem Zeitpunkt alle Punkte in Verbindung gebracht werden müssen, was Probleme bei der Skalierung mit sich bringt.
Fuzzy Clustering (c-Means)
Fuzzy Clustering (auch c-Means oder Soft-k-Means genannt) ist, wie der Name schon sagt, ein Algorithmus, der Punkte nicht fix einem Cluster zuordnet sondern mit Wahrscheinlichkeiten arbeitet. Folglich kann jeder Datenpunkt zu verschiedenen Wahrscheinlichkeiten mehreren Clustern gehören.
Wie an den alternativen Namen c-Means bzw. Soft-k-Means zu sehen, basiert der Algorithmus auf dem gleichen Prinzip wie k-Means, berechnet allerdings Wahrscheinlichkeiten statt fixe Clusterzugehörigkeiten. Ebenso werden die Clustermittelpunkte basierend auf den Wahrscheinlichkeiten berechnet. Somit liefert Fuzzy Clustering eher eine Verteilung der Punkte als Zuordnungen.
Anwendungsgebiete und Besonderheiten von Fuzzy Clustering
Die gleichen Vor- und Nachteile von k-Means gelten auch für Fuzzy Clustering. Was allerdings ein Unterschied ist, ist die sanfte Zuordnung zu Clustern mittels Wahrscheinlichkeiten, was andere Anwendungsfälle zulässt. Zum Beispiel in der Zuordnung von Kunden macht es sehr viel Sinn, jeder Person eher eine “Nähe” zu einem Prototyp zuzuweisen als binäre Segmente. Als Problem zeigt sich allerdings, dass durch die Multidimensionalität der Wahrscheinlichkeiten auch eine höhere Anforderung nötig ist als bei k-Means.
Weitere Clustering Algorithmen
- Model-based Clustering:
- Divisive Clustering:
- Relocation Algorithms:
- K-Medoids: Ähnlich wie K-Means, jedoch wählt K-Medoids echte Datenpunkte als Mittelpunkte statt des Durchschnitts aller Objekte.
- Subspace Clustering: Subspace Clustering versucht 2D-Bereiche zu definieren, die ähnliche Objekte zusammen fasst.
- Projection Technique:
- Co-Clustering Technique:
- K-Prototypes: Gut geeignet für den Umgang mit kategorischen Variablen.
Was ist Kobold AI?
Kobold AI bietet den Einsatz künstlicher Intelligenz ohne technisches Vorwissen. Einfach, schnell und günstig KI anwenden, um Mehrwert durch Daten zu generieren.
Wie es funktioniert erklärt unser interaktives Video:
Häufige Fragen im Clustering (FAQ)
Was ist eine Distanzmetrik?
Die Distanzmetrik definiert die Berechnung der “Ähnlichkeit” zwischen zwei Punkten. Als einfachsten Fall kann man im eindimensionalen Raum einfach die Differenz zwischen zwei numerischen Werten (zum Beispiel Alter) nehmen, aber auch die absolute Differenz, die Potenz der Differenz, die logarithmische Differenz sind mögliche Ansätze für eine Distanzmetrik.
Interessanter wird es offensichtlich wenn man über eine mehrdimensionale Distanzmetrik spricht. Hier gibt es eine ganze Bandbreite an etablierten Distanzmetriken wie die euklidische Distanz, die Manhattan Distanz oder die Cosine Distanz. Jede der Metriken hat wie üblich Vor- und Nachteile und in jedem Machine Learning Algorithmus spielt die Distanzmetrik eine zentrale Rolle, da sie definiert wie sensitiv der Algorithmus auf Abweichungen reagiert und wie er sie interpretiert.
Wie legt man die optimale Anzahl an Clustern fest?
Oft ist unklar, wie viele Cluster man erstellen möchte. Vor allem bei Partitionsmethoden wie k-Means muss man sich vorab entscheiden, auf welches “k” man optimieren möchte. Hierbei kommen Methoden wie die Elbow-Method, das Average Silhouette Model oder die Gap Statistic Method zum Einsatz. Im Prinzip geht es immer darum, durch die iterative Berechnung verschiedener Clustergrößen (z.B. 2 bis 10) die Anzahl zu finden, die am besten zwischen den Clustern differenziert.

Neben diesen statistischen Berechnungen werden in der Praxis wird allerdings auch oft mit verschiedenen Clustergrößen experimentiert, um eine passende Größe für das vorliegende Problem zu finden. Hierbei werden auch teilweise statistisch optimale Analysen ignoriert, da die Fragestellung aus dem Business (z.B. “Ich möchte vier Newsletter-Gruppen”) Bedingungen vorgeben oder Erfahrung (z.B. “Wir denken in drei Kundenmaturitäten”) einen großen Einfluss haben.
Um all diese Information zusammen zu führen, gibt es in verschiedenen Softwarepaketen inzwischen auch kumulative Herangehensweisen, die viele Optimierungsmethoden (z.B. Elbow, Silhouette..) einsetzt und dann die häufigste Clusteranzahl als Empfehlung ausgibt. In R ist dies zum Beispiel NbClust() im gleichnamigen Paket, das ungefähr 30 Methoden für k-Means vergleicht.
Welche Rolle spielt Datenqualität im Clustering?
Datenqualität ist wie in jeder datenbasierten Vorgehensweise hochrelevant. Da Clustering direkt auf den Daten arbeitet und diese als Indikatoren für die Gruppierungen nutzt, hat schlechte Datenqualität selbstverständlich nochmals schwerwiegendere Folgen.
Neben genereller schlechter Datenqualität gibt es noch vereinzelte Fälle von Ausreissern. Hier gibt es zwei Faktoren zu beachten. Einerseits ist Clustering sehr gut geeignet um Ausreisser zu detektieren, was somit direkt der Anwendungsfall wäre.
Ist dies jedoch nicht das Ziel, kann der Algorithmus durch Ausreisser negativ beeinflusst werden. Vor allem Algorithmen die direkt auf Distanzmetriken arbeiten wie k-Means sind sehr anfällig für Outlier. Daher gilt es, die Datenqualität sehr kritisch zu betrachten und ggf. zu korrigieren.
Wie gehe ich mit Redundanz (Features mit hoher Korrelation) im Clustering um?
Redundante Features, also Variable die sich sehr ähnlich oder sogar komplett gleich sind, haben einen hohen Einfluss im Clustering. Bei ungewichteten Attributen führt dies im einfachsten Fall dazu, dass ein Feature (z.B. Gewicht) doppelt (z.B. einmal in Gramm und einmal in Kilogramm) gewichtet wird.
Nun gibt es mehrere Ideen, wie man diese Redundanz / Korrelation von Features angeht. Der erste Weg ist definitiv sich einer Korrelation bewusst zu werden, also mittels einer Korrelationsmatrix o.ä. Analysen die Korrelationen zu identifizieren. Es gibt auch Clustering-Distanzmetriken die Korrelationen zwischen Metriken als Distanz nutzen, namentlich die Mahalanobis distance.
Nebst der Einsicht dass es so ist, muss man entscheiden ob und falls ja wie man korrigiert. In vielen Fällen möchte man redundante Features ausschließen oder noch besser heruntergewichten. Zweiteres hat den Vorteil, dass minimale Interaktionseinflüsse nicht entfernt werden, was bei einem kompletten Ausschluss der Fall ist.
Generell sei gesagt, dass hohe Korrelationen ein starkes Gewicht auf eine bestimmte Metrik legen können, die unerwünscht ist. Daher gilt es sich vorher sehr intensiv mit den vorliegenden Daten vertraut zu machen, um Redundanzen zu identifizieren.
Wie gehe ich mit sehr vielen Variablen um?
Eine sehr hohe Anzahl an Variablen führt meist zu sehr hoher Laufzeit der Algorithmen und führt gegebenenfalls dazu, dass minimale Effekte zur Differenzierung der Cluster genutzt werden. Was oft eingesetzt wird ist, ist eine principal component analysis (PCA) zur Featureselection. Diese Auswahl von Metriken überprüft, welche Features überhaupt eine hohe Varianz innerhalb der Daten auslösen. Somit kann die Anzahl der Variablen reduziert und andere Probleme umgangen werden.
Welche Vorverarbeitungen (Preprocessing) sind im Clustering üblich?
Die Vorverarbeitungsschritte sind abhängig vom eingesetzten Clusteringalgorithmus, aber es gibt einige generelle Schritte die vorab durchgeführt werden:
- Missing Data / fehlende Daten: Wenn einzelne Dateneinträge fehlen, muss entschieden werden wie damit umgegangen wird. Zum Beispiel durch entfernen der Einträge, der Attribute oder Imputation kann Missing Data behoben werden.
- Curse of dimensionality: Bereits kurz angesprochen kann eine sehr hohe Anzahl an Features negative Effekte haben. Daher versucht man die Anzahl auf maximal ca. 20 – 30 Features zu halten.
- Data Normalization: Daten in einem Ausgangsformat kann massive Auswirkung auf die Ergebnisse der Berechnung der Distanzen haben. Zum Beispiel hat eine Distanz in der Variable “Gewicht” eine höhere Auswirkung als “Länge in Millimeter”. Daher normalisiert man die Daten, zum Beispiel mittels z-Transformation.
- Categorical Variables: Nicht alle Algorithmen können kategorische Features, also zum Beispiel “Geschlecht”, verarbeiten. Entsprechend müssen die Daten entweder in Zahlen transferiert werden (z.B. “groß / klein” in “10 / 100”) oder mittels One-Hot-Encoding in binäre Variablen (z.B. “schwarz / grün” in “schwarz -> 1 / 0, grün -> 0 / 1).
Die Rolle von Clustering in Unternehmen
Als eine der zentralen Kategorien im Bereich Machine Learning, Clustering nimmt eine sehr zentrale Rolle in Unternehmen ein, die Data Science einsetzen. Clustering hat eine Bandbreite an Einsatzmöglichkeiten und kann somit kreativ auf viele Probleme im Business angewandt werden.
Fachlich ist Clustering auch etwas einfacher als komplexe neuronale Netzwerke oder Time Series Analysen, so dass es gut auch von Junior Data Scientists oder anderen Kollegen eingesetzt werden kann. Und der Effekt kann sehr hoch sein: Wenn ich meine Kunden besser kennenlerne, Ausreisser in meinen Transaktionen dargelegt bekomme oder die Datenqualität sukzessive automatisch erhöhen kann, hat dies einen großen Wert.
Daher empfehlen wir definitiv den Einsatz von Clustering im Unternehmen und freuen uns über spannende Anwendungsfälle.
Weiterführende Informationen & Tutorials
Clustering in python
Folgend ein Video-Tutorial wie man Clustering in python umsetzen kann:
Clustering in R
Hier eine Version eines Video-Tutorials über Clustering in R:
Buchempfehlung zu Clustering: Algorithmen und Methoden
Eine breitere Einführung, aber dennoch sehr detailliert auf das Thema Clustering bezogen ist das Buch “Practical Statistics for Data Scientists: 50+ Essential Concepts Using R and Python”. Das Tolle am Buch ist, dass nebst theoretischer Konzepte und praktischer Übungen auch immer wieder ein Schritt zurück gegangen wird um sich die Frage zu stellen “Warum brauchen wir dies?”.
Was ist Kobold AI?
Kobold AI bietet den Einsatz künstlicher Intelligenz ohne technisches Vorwissen. Einfach, schnell und günstig KI anwenden, um Mehrwert durch Daten zu generieren.
Wie es funktioniert erklärt unser interaktives Video: