
Ein Digital Twin, auf Deutsch “digitaler Zwilling”, ist eine möglichst detailgetreue, individuelle digitale Repräsentation eines physischen Objekts. Als Objekt kann vieles dienen: Menschen, Maschinen, Fahrzeuge oder Produkte.
Infografik Digital Twins

Inhaltsangabe
Was sind Digital Twins? Definition und Abgrenzung digitaler Zwillinge
Geprägt ist das Konzept “Digital Twins” davon, dass Daten nicht für die Allgemeinheit an Entitäten (z.B. “Wie werden unsere Fahrzeuge genutzt?”) gesammelt werden, sondern vom Entstehungsprozess (z.B. Simulation, Fertigung) über die Logistik (z.B. Bestellung, Lieferung) bis zum Einsatz (z.B. Nutzungsdaten) für jede Instanz aufgenommen und zugeordnet werden.
Das Ziel von digitalen Zwillingen ist es, einerseits eine Nachverfolgbarkeit der Entwicklung von Entitäten zu schaffen (z.B. “Warum ist der Herd schon nach 2 Monaten defekt?”), andererseits natürlich auch direkt mit diesen Entitäten und deren individuellen Historie zu interagieren (z.B. “Dieses Heizelement wurde bisher immer auf Höchstlast eingesetzt, wir müssen den Wartungszyklus verkürzen”).
Einfach gesagt sind Digital Twins die Erfassung und Nachverfolgung von allen entstehenden Daten im Lebenszyklus eines Produkts, einer Person oder einer anderen Entität zur datenbasierten Analyse. Dabei gilt es, die Daten nicht einseitig zu übermitteln, zu erfassen und zu nutzen, sondern bilateral. Die Entität (Produkt, Service, Maschine, etc) übermittelt Daten, empfängt aber gleichermaßen ebenso Daten um diese für sich einzusetzen.
Beispiele für verschiedene Arten von Digital Twins

Digital Product Twin: Jedes physisches Produkt hat seinen eigenen Zwilling
Vor allem bei technischen Produkten bietet sich ein digitaler Zwilling geradezu an. Ob nun die Bohrmaschine oder der Herd, das Mobiltelefon oder die Heizungsanlage: Alle diese Dinge produzieren Daten und können durch individuelle Datenanalyse wiederum effizienter eingesetzt werden. Die Datenaufnahme des Digital Twins startet mindestens in der Fertigung, oft schon eher in der Entwicklung, geht dann über die Qualitätskontrolle, die Logistik, den Handel bis zum Endverbraucher und dessen Nutzungsverhalten. Alle Datenquellen müssen kohärent integriert, querverbunden und zusammengeführt werden, um das digitale Abbild des physischen Produkts korrekt zu repräsentieren.
Digital Twins in Manufacturing: Eine Maschine, viele Daten
Ein Anwendungsgebiet von Digital Twins von dem sich viele einen hohen Effekt versprechen ist die Fertigung (Manufacturing). Vor allem große Fertigungsmaschinen bestehen oft aus einer langen Historie an Simulationen, Bauteilen, Teilreparaturen, Einsatzzwecken und vieles mehr. Wenn diese Daten mit Bewegungsdaten (z.B. welche Produkte werden gefertigt, wann wurde wie gewartet) kombiniert werden, erlaubt dies einen 360° Blick auf die Maschine und deren aktuellen Status. Dies erlaubt es, direkt die Effizienz der Fertigung zu erhöhen: Vorausschauende Wartung (predictive Maintenance), Auslastungspläne, Nachverfolgung von Gründen für Ausfallzeit, Produktqualitätskontrolle und vieles mehr.
Digital Customer Twin: Der Kunde als digitaler Zwilling
Ein weiterer interessanter Einsatzzweck ist die holistische Betrachtung eines Kunden und die Kombination aller Kontaktpunkte die diese Person mit dem Unternehmen hat. Ob nun Bestellungen, Newsletterinteraktionen, Servicekontakt und andere Datenquellen: Die konsolidierte Historie eines Kunden mitsamt Stammdaten und deren Änderungen erlaubt einen hohen Grad an Personalisierung (z.B. Customer Churn Prediction) und ist die Basis für ein hohes Maß an Kundenzentrierung. Heute sind die Daten über Kunden meist in verschiedenen Systemen – oder werden gar nicht strukturiert erfasst.
Digital Services Twin: Wie Dienstleistungen digital repräsentiert werden
Aber nicht nur physische Dinge wie Maschinen, Produkte und Menschen können mittels digitaler Zwillinge repräsentiert werden, sondern auch Services oder Dienstleistungen. Vom Entstehungsprozess über Pricing, vom Verkauf zum Einsatz, von Teilnehmern über Ratings – auch Dienstleistungen können durch eine umfassende verknüpfte Datenhaltung erheblich aufgewertet werden. Dies erlaubt es, das Portfolio des Unternehmens kontinuierlich zu verbessern, Auslastung zu steuern und Querverbindungen zu anderen Twins wie dem Kunden oder Produkt zu ziehen.
Was sind die Vorteile von Digital Twins?
Nachdem das Prinzip dargestellt wurde, möchten wir auf ein paar Vorteile von Digital Twins eingehen:
- Datenkonsolidierung: Da für jeden Digital Twin alle dazugehörigen Daten erfasst werden, wird sowohl technisch als auch aus Data Governance Sicht eine Art Mini Data Lake kreiert.
- Erfassung des gesamten Lebenszyklus: Im digitalen Zwilling werden nicht nur Daten der Nutzung erfasst, sondern von Beginn bis Ende des Lebenszyklus.
- Prozessdokumentation und Optimierung: Indem ein Digital Twin sukzessive aufgebaut wird, kann man direkt darunter liegende Prozesse ableiten und Process Mining betreiben.
- Hohe Granularität: Individuell erfasste Daten haben zudem eine sehr hohe Granularität, die mehr Anwendungsfälle als aggregierte Daten erlauben.
- Einsatz für Data Science: Durch die Konsolidierung aller zu einer Entität gehörigen Daten, hat man ein großes Anwendungsfeld für Advanced Analytics, Machine Learning und mehr.
Was ist Kobold AI?
Kobold AI bietet den Einsatz künstlicher Intelligenz ohne technisches Vorwissen. Einfach, schnell und günstig KI anwenden, um Mehrwert durch Daten zu generieren.
Wie es funktioniert erklärt unser interaktives Video:
Abgrenzung Digital Twins und andere naheliegende Konzepte
Die Idee, Daten zu Produkten und Personen zu erfassen ist per se nicht neu. Es gibt selbstverständlich seit Jahren Stammdatensysteme, die Informationen zu Entitäten erfassen, als auch neuere Konzepte wie einzelne Dinge (IoT) kommunizieren. Im folgenden möchten wir kurz auf die Positionierung der Digital Twins in einer Reihe naheliegender technischer Konzepte eingehen.
Was ist der Unterschied zwischen einem Stammdatensystemen (z.B. MDM, PIM, CRM, PLM, PDM) und Digital Twins
Ein Stammdatensystem erfasst die Daten zu Produkten (z.B. Product Information Management, PIM), für jeden Kunden (z.B. Customer Relationship Management, CRM) oder auch zum Entstehungsprozess einer Maschine oder Dienstleistung (z.B. Product Lifecycle Management, PLM). Daher ist die Idee von digitalen Zwillingen sehr nah an dieser Art von Systemen angesiedelt.
Es gibt jedoch drei erhebliche Unterscheidungskriterien zwischen Digital Twins und Stammdatensystemen wie MDM, PIM, CRM, PLM oder PDM.
- Stammdatensysteme erfassen oft nur den “Prototyp”, also das generische Produkt (z.B. PIM), nicht jede einzelne Entität
- Stammdatensysteme haben selten alle Datenquellen integriert, die zu einem Entitätstyp existieren (z.B. CRM hat selten Daten von Service, Webanalytics, Hotline, Webshop, etc integriert)
- Stammdatensysteme folgen einem bestimmten operativen Prozess und bilden nicht die Basis für eine zentralisierte, individuelle, komplette Datensammlung um diese Daten weiterzuverwenden (Advanced Analytics, Data Science, Machine Learning, etc)
Folglich gibt es – je nach Stammdatensystem – gegebenenfalls bereits eine hohe Schnittmenge an Daten, die auch für den Digital Twin genutzt werden können. Das Ziel der digitalen Zwillinge ist jedoch, dass diese Daten konsolidiert, individuell und zur Weiterverarbeitung erfasst werden, was oft nicht deckungsgleich mit Stammdatensystemen ist.
Was ist der Unterschied zwischen dem Internet of Things (IoT) und Digital Twins
Das Internet der Dinge (IoT) ist ein Konzept, bei dem jedes technische Produkt individuell Daten sendet und empfängt, um mittels künstlicher Intelligenz Vorhersagen zu treffen. Diese hyperpersonalisierten Daten eines Endgeräts (Edge Device) sind selbstverständlich sehr wertvoll im Konzept von Digital Twins. Es gibt jedoch zwei Unterschiede zwischen IoT und digitalen Zwillingen: Zum einen fokussiert sich das Internet der Dinge auf die Kommunikation von Geräten im Einsatz, zum anderen deckt IoT keine historischen Daten wie Entwicklung oder verwendetes Material ab. Folglich deckt das Internet of Things zwar den mittleren Teil des Lebenszyklus ab, beachtet aber nicht alle Datenquellen (z.B. Serviceanfragen, Manufacturing Daten) und Vorlaufinformationen.
Was ist der Unterschied zwischen Big Data Analytics / Event Streaming und Digital Twins
Big Data Analytics, vor allem im Zusammenhang mit Event Streaming, ist ein weiteres Konzept das sehr nah am Thema Digital Twins verortet wird. Generell ist es jedoch nur ein Anwendungsfall von den so erfassten Datenmengen: Werden via Event Streaming Daten übermittelt, können die direkt analysiert werden; aber die Zuordnung, Nachhaltung und langfristige Analyse im Zusammenhang auf das individuelle Gerät ist die Erweiterung des Konzept durch digitale Zwillinge.
Beispiel-Architektur eines Digital Twins
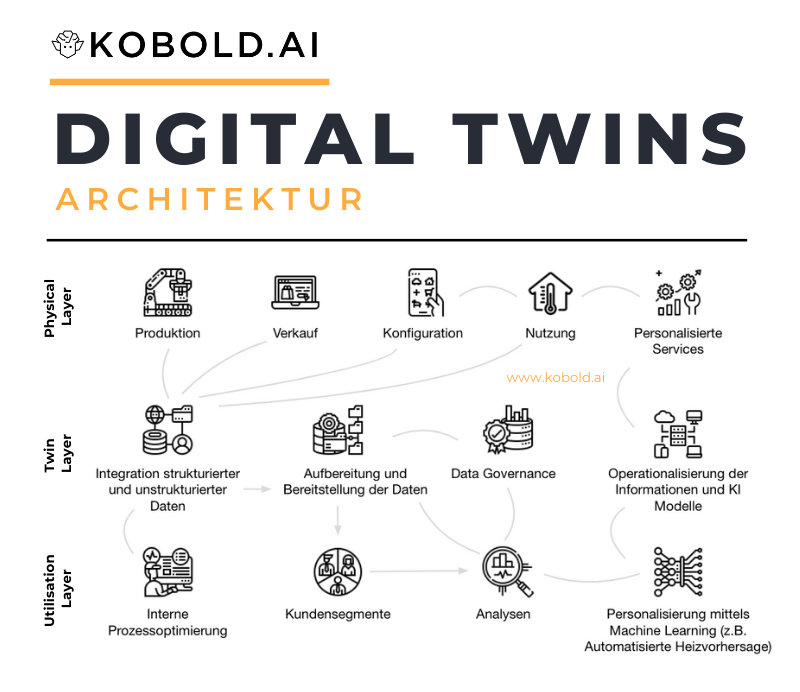
Ein Digital Twin kann auf viele Arten aufgebaut werden. Generell gibt es viele Anbieter für derartige Software, andererseits kann das Konzept auch selbst umgesetzt werden. Verallgemeinert besteht die Architektur eines Digital Twins aus drei Ebenen: Dem Physical Layer, dem Twin Layer und dem Utilisation Layer.
Physical Layer
Die physische Ebene ist die reale Manifestierung der Entität. Ob nun Mensch oder Maschine: In jedem Fall produziert die physische Ebene über ihren gesamten Lebenszyklus Daten. Diese Daten gilt es dann zu messen, erfassen und im Twin Layer zu konsolidieren.
Twin Layer
Der Twin Layer ist das Herzstück der gesamten Architektur. Er besteht aus mehreren Datenbanksystemen für strukturierte und unstrukturierte Daten sowie umfängliche Dokumentation. Gleichermaßen wird üblicherweise ein Access Block eingefügt, um den Digital Twin verfügbar für das Utilisation Layer zu machen.
Utilisation Layer
Als Utilisation Layer werden alle Aspekte zusammengefasst, die den Digital Twin einsetzen. Ob Optimierung innerhalb der Fertigung, die Anwendung von künstlicher Intelligenz oder das ausspielen von individueller Software in das physical Layer – alle Vorgehen die Daten des Twins extrahieren und einsetzen, sind hier beheimatet.
Gemeinsam erlauben alle drei Layer die Überführung der physischen Repräsentation in den digitalen Zwilling und dessen Einsatz in einer Vielfalt von Anwendungsfällen. Nur wenn alle drei Ebenen ineinander übergehen erlaubt es ein effizientes Vorgehen bei der Nutzung des entstandenen Mehrwerts.
Die Relevanz von Digital Twins in der Data Driven Company
Digital Twins sind als logische Kombination von Data Lakes und dem Internet of Things eines der neueren Konzepte in der Welt der Daten. Dabei vereinen sie eine Bandbreite an technologischen wie auch konzeptuellen Fortschritten: Individuelle Daten, konsolidiert und dokumentiert als Basis für Anwendungsfälle in Data Science, Automatisierung und Optimierung.
Folglich sind die digitalen Zwillinge eine Richtung in die sich jede Data Driven Company bewegen sollte. Im Optimalfall setzen die digital Twins auf andere Bereiche wie dem Data Lake auf und sind daher in ihrer Implementierung gering, sondern erfordern eher eine Erweiterung des Wirkungsbereichs.
Sind Digital Twins einmal etabliert, eröffnen sich eine Bandbreite an Applikationen. Von Hyperpersonalisierung über Prozessoptimierung wirkt der Datentransfer in beide Richtungen und fokussiert, wofür die Data Driven Company stehen sollte: Die Generierung von Mehrwert durch Daten.
Was ist Kobold AI?
Kobold AI bietet den Einsatz künstlicher Intelligenz ohne technisches Vorwissen. Einfach, schnell und günstig KI anwenden, um Mehrwert durch Daten zu generieren.
Wie es funktioniert erklärt unser interaktives Video: