
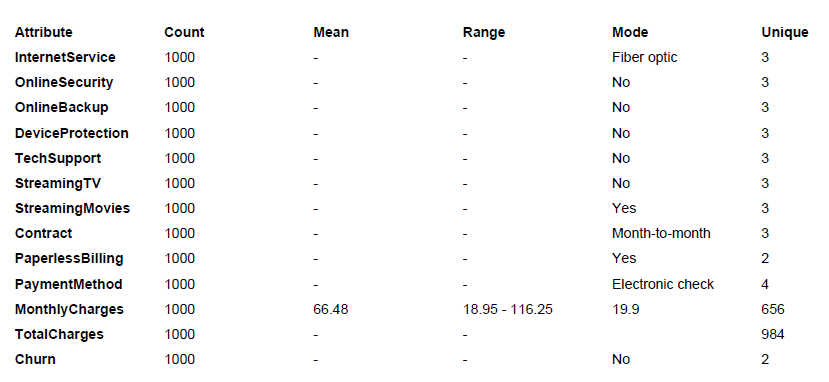
Data-Driven Personas
499,00 €
Personas sind ein Werkzeug für mehr Kundenzentrierung im Marketing, Vertrieb und Produktentwicklung. Wir erstellen die Personas aus echten Stamm- und Verhaltensdaten.
Beschreibung
Diese Daten brauchen wir
- Inhalt: Stammdaten, Verhaltensdaten, Transaktionsdaten
- Quellen: CRM, ERP, e-Commerce, Newsletter
- Format: Eine Reihe = ein Kunde, beliebig viele Spalten
Kunden sind das Herzstück eines jeden Unternehmens. Ohne Kunden kein Umsatz, ohne Umsatz kein Unternehmen. Aber es ist oft schwierig zu verstehen, wie man Kunden am besten bedient. Ein Ansatz um dieses Kundenverständnis zu verbessern sind sogenannte Personas. Doch was ist das?
Was sind Data-Driven Personas?
“Die Data-Driven Personas erlauben es uns, unsere Kundengruppen greifbar zu machen. Diese Informationen bringen einen strategischen wie auch operativen Mehrwert, um unsere Kundenbeziehungen zu stärken und das beste Erlebnis zu bieten.”
Erik Markert, Leiter Lesermarkt Digital, Augsburger Allgemeine
Kunden verstehen: Was sind Personas und wofür werden sie eingesetzt?

Personas sind die Repräsentation einer Kundengruppe durch eine Art Personenprofil. Das Profil bekommt einen Namen und wird angereichert mit vielen qualitativen Informationen, wie zum Beispiel Kundenumfragen, Erfahrungen des Vertriebs oder dem, was die Service-Abteilung täglich erfährt.
Am Ende ist das Ziel von Personas, die große Varianz an Kunden in möglichst wenige (2-8) Profile zu verpacken. Diese Personas werden dann in Produktentwicklung, strategischen Entscheidungen, Service-Definition und anderem eingesetzt um möglichst viel Kundenbedürfnisse abzudecken.
Die Probleme mit qualitativen Personas
Personas sind weit verbreitet. Und trotz sehr großer Verfechter des Vorgehens stoßen sie immer wieder an ihre Grenzen:
- Interviews als Informationsquelle: Personas werden üblicherweise vor allem durch Interviews ausgeschmückt. Somit sind es persönliche Meinungen, die sehr stark das Bild der Kunden beeinflussen. Und diese persönlichen Meinungen können nur einen Teil der Realität abbilden oder dieser sogar widersprechen.
- Statische Profile: Personas werden meist durch großflächige Projekte ausgearbeitet. Leider bewegt sich die Welt schnell und somit ändern sich auch oft und schnell die Bedürfnisse und Verhaltensweise von Kunden. Somit bildet eine qualitative Persona immer nur die Vergangenheit, selten die Gegenwart ab.
- Kein System-Bezug: Personas sind hervorragend, um Ideen zu entwickeln und kundenzentriert zu denken. Aber möchte man dann Maßnahmen wie Marketing-Kampagnen oder individuellen Kundenservice anhand dieser Personas ausrichten, hat man schnell ein Problem. Denn die qualitativen Attribute können selten auf den Kundenbestand transferiert werden. Somit gibt es kaum eine Möglichkeit, Personas auch in Systemen (z.B. CRM, Service) zu repräsentieren.
Was sind Data Driven Personas?
Wir haben ein Vorgehen entwickelt, das die Vorteile von Personas und den Mehrwert von Daten kombiniert. Genauer werden Data-Driven Personas bei Kobold AI durch den Einsatz von künstlicher Intelligenz erstellt. Hierbei wird der Algorithmustyp “Clustering” angewandt. Clustering gruppiert Einträge anhand der Ähnlichkeit ihrer Attribute zusammen.

Nutzt man beispielsweise als Datengrundlage den Jahresumsatz, Geschlecht und Alter von Kunden nutzt, werden Kunden mit gleichem Alter, ähnlichem Umsatz und gleichem Geschlecht zusammengefasst.
Das interessante: Unsere Algorithmen können Daten jeder Art nutzen, um ähnliche Verhaltensweisen, Stammdaten und mehr zu gruppieren. Somit werden Segmente identifiziert, die dem menschlichen Auge vielleicht verdeckt geblieben wären.
„Mit den Data-Driven Personas können wir unsere Multichannel-Strategie optimal an die Bedürfnisse unserer Kunden anpassen. Individuelle Angebote und eine bessere Betreuung sorgen für eine hohe Kundenbindung und -zufriedenheit. Ein klarer Vorteil im Zuge der Digitalen Transformation unserer Branche.“
Michael Kluge, CMO, BÄR Gruppe
Wie genau? Das erklärt der nächste Abschnitt, in dem wir vorstellen wie wir dabei vorgehen.
Wie funktioniert Kobold AI?
Data-Driven Personas bei Kobold AI: Vorgehen und Ergebnisse
Kobold AI ist ein Webshop für Self-Service KI-Produkte. Das heißt jeder Besucher kann ganz einfach einen Anwendungsfall auswählen, die eigenen Daten dazu hochladen und bekommt vollautomatisch das Ergebnis geliefert.
Um unser Produkt “Data-Driven Personas” besser zu verstehen, hier Details über unser Vorgehen und die gelieferten Ergebnisse.
Initiale Datenanalyse
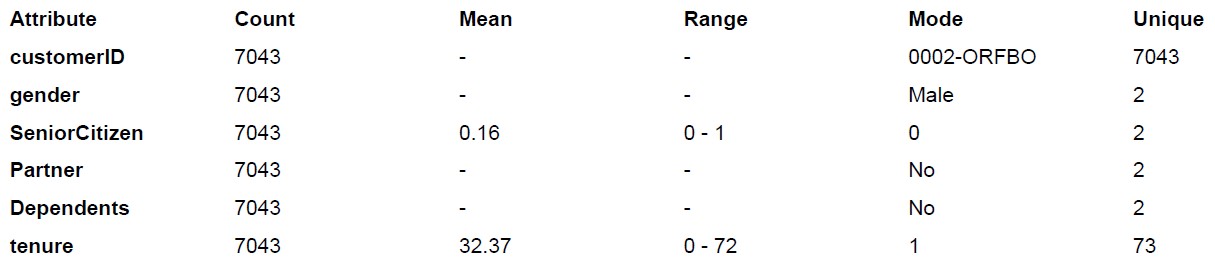
Zu Beginn nutzen wir einfache statistische Analysen um die vorliegenden Daten zu überprüfen. Diese initiale Datenanalyse erlaubt eine Transformation der Daten für weitere Verarbeitung, Eingabe für das Data Pre-Processing, aber vor allem für den Kunden um nochmal zu überprüfen, ob die gefundenen Daten (Mittelwert, Spannweite, Modus, Anzahl an Ausprägungen) der Erwartung entsprechen.
Tauchen bei der Überprüfung der initialen Datenanalyse unerwartete Inhalte (zum Beispiel zu große Einträge, zu viele einzigartige Einträge) auf, empfehlen wir eine Datenqualitätsanalyse von Kobold AI um dem nachzugehen.
Datenqualität und Vorverarbeitung

In Schritt “Pre-Processing” findet eine Vorverarbeitung der gelieferten Daten statt. Die Datenqualität wird geprüft und schlechte Attribute und Zeilen ausgeschlossen. Zudem werden Attribute, die sich schlecht in der Gruppenbildung verarbeiten lassen (z.B. eine Spalte mit nur einzigartigen Texteinträgen) ausgeschlossen, um ein möglichst optimales Ergebnis zu ermöglichen. All diese Schritte finden vollautomatisch statt, um die Daten für den Einsatz von Künstlicher Intelligenz vorzubereiten.
Gruppenidentifizierung durch Clustering
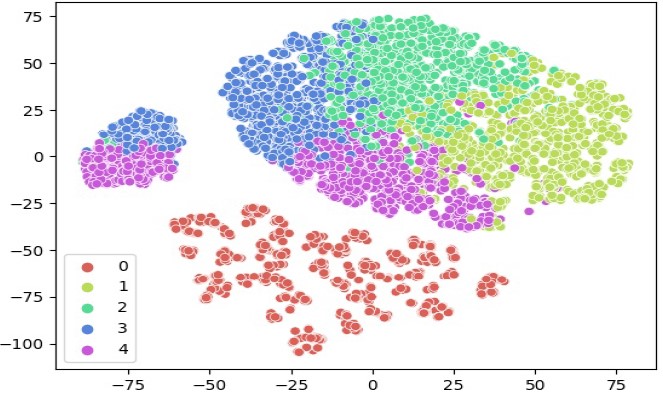
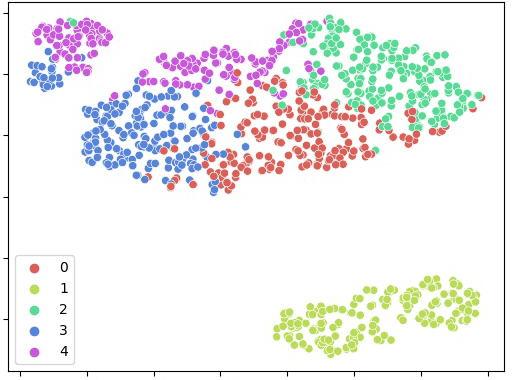
In diesem Schritt setzen wir maschinelles Lernen aus dem Bereich der künstlichen Intelligenz ein, um homogene Gruppen zu bilden. Der eingesetzte Algorithmus “Clustering” sucht für jeden Eintrag möglichst ähnliche Einträge.
Durch dieses Vorgehen können Cluster identifiziert werden, die ähnliches Verhalten zusammenfassen und dadurch als Persona interpretiert werden können. Vollautomatisch beachtet unser Algorithmus dabei Ausreißer und definiert, wie viele Gruppen sinnvoll gebildet werden sollen.
Beschreibung der Gruppen durch Statistiken
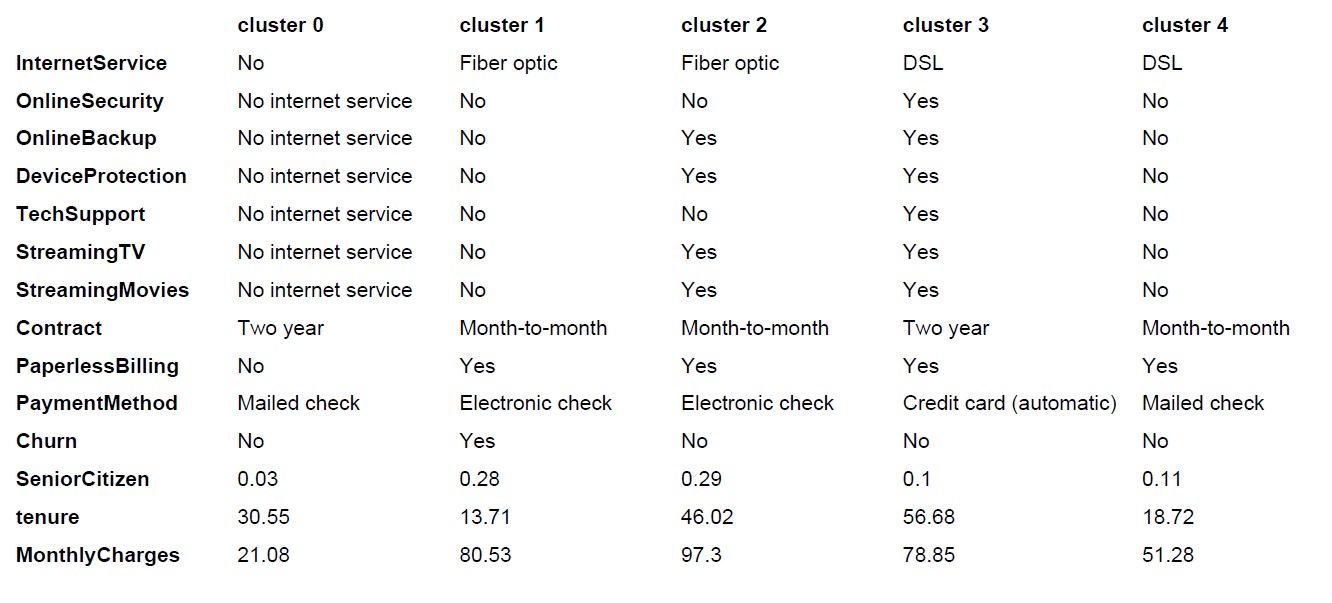
Wenn die Kundengruppen identifiziert wurden, können sie einfach und schnell beschrieben werden. Für jeden Cluster kann jedes Attribut analysiert und dargestellt werden, zum Beispiel das häufigste Auftreten oder der Mittelwert.
Aus dem Bild der Datenbeschreibung ergibt sich die Beschreibung der Gruppen. In kurz, die Datenanalyse definiert die Besonderheiten jedes Clusters im Vergleich zu den anderen. Diese Information ist besonders wichtig für die qualitative Interpretation der Cluster.
Weist ein Cluster zum Beispiel besonders häufig ein Attribut im Vergleich zu den anderen Gruppen aus, trägt dieses Attribut dazu bei, dass dieses Segment von den anderen abgegrenzt wurde. Noch mehr Informationen zu den definierenden Attributen finden sich in der detaillierten Analyse.
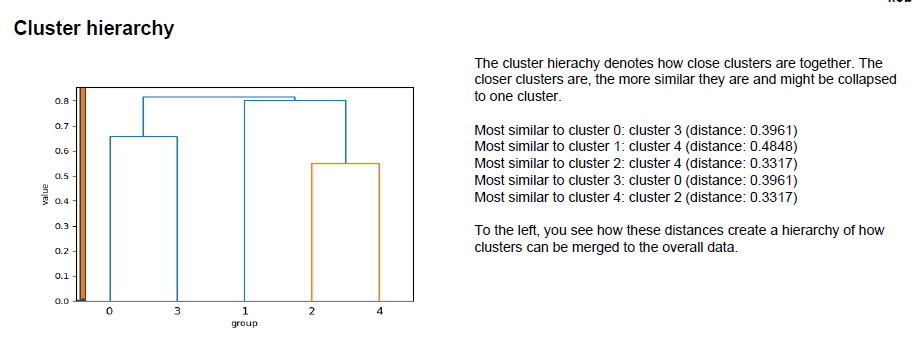
Clusterhierarchie zum Verständnis der Ähnlichkeit der Gruppen
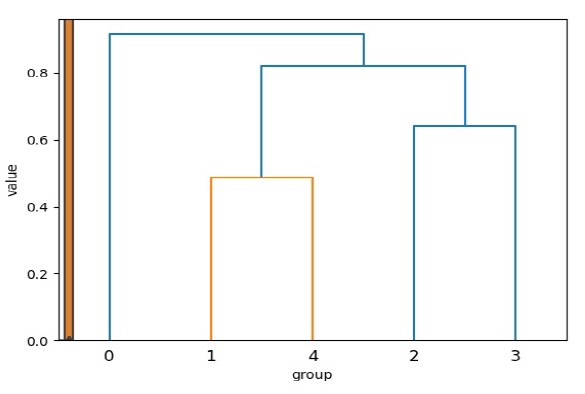
Um die Ähnlichkeiten zwischen den Gruppen zu quantifizieren, berechnen wir eine Hierarchie zwischen den Inhalten der identifizieren Gruppen. Im obigen Beispiel sind Gruppen 1 und 4 am ähnlichsten, was eine weiterführende Interpretation deren Attribute erlaubt.
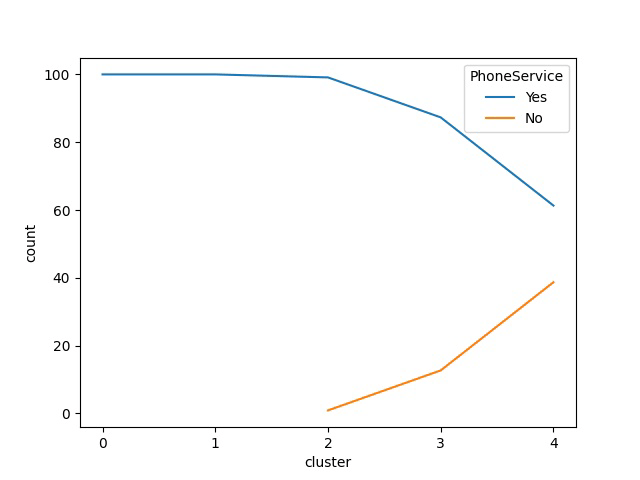
Detaillierte Attributanalyse pro Cluster
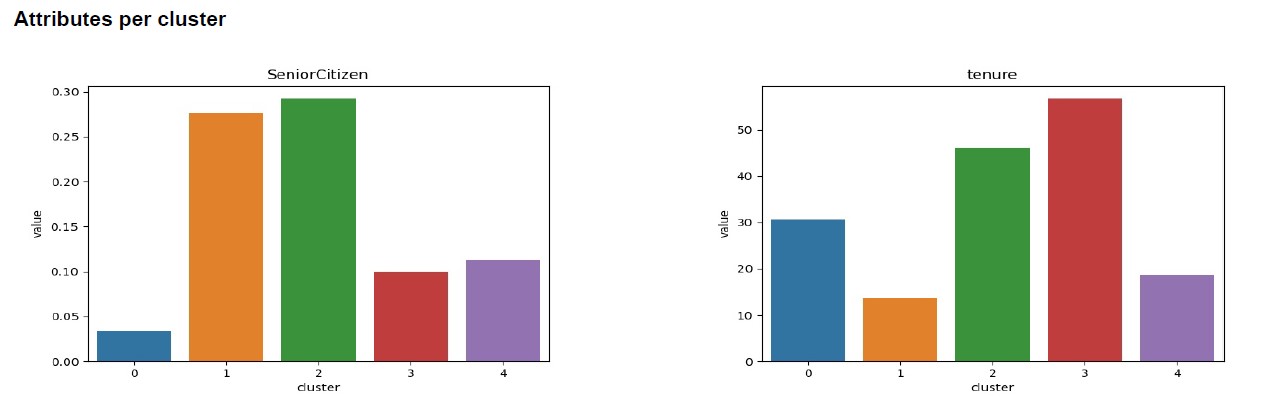
Unser Produkt schließt mit einer detaillierten Analysen für jedes Attribut ab. Diese Detailanalyse erlaubt es, die definierenden Attribute für jeden Cluster zu identifizieren. Besonders im Vergleich zu den anderen Gruppen wird dadurch schnell klar, weshalb ein Cluster gebildet wurde.
Ist ein Attribut zum Beispiel über alle Cluster hinweg gleich, trägt es wenig zur Gruppenbildung bei. Ist es sehr unterschiedlich, im besten Fall binär (Ja / Nein), ist sehr schnell klar, dass es wichtig ist die Persona von den anderen abzugrenzen.
Zusammengefasst werden die Data-Driven Personas durch Identifizierung von relevanten Daten, Gruppierung basierend auf ähnlichen Einträgen und möglichst Detaillierte Beschreibung der resultierenden Cluster erstellt. So hat man ein klares Bild wie und weshalb Gruppen erstellt wurden. Dies erlaubt den nahtlosen Übertrag in eine Persona-Bezeichnung und Ausspielung im Unternehmen.
Welche Daten werden bei datenbasierten Personas eingesetzt?
Hier ein Beispiel an Daten und Informationen die man im Clustering einsetzt:
- Einkaufsverhalten (z.B. Anzahl Einkäufe, letzter Einkauf in Tagen, Umsatzhöhe)
- Kundendaten (z.B. Alter, Geschlecht oder Unternehmensgröße, Umsatz bei B2B)
- Historische Daten (z.B. Anzahl an Tage seit Erstkauf)
- Präferenzen (z.B. Umsatzverteilung auf Einkaufskategorien)
- Verhaltensdaten (z.B. Nutzung der Website, Reklamation)
- Bedürfnisdaten (z.B. Anzahl an Kontaktpunkten zum Kundenservice)
Je nachdem, welche Daten man bereit stellt, hat man auch die Möglichkeit die Personas basierend auf bestimmten Daten zu erstellen. Setzt man zum Beispiel viele Daten zum Einkaufsverhalten ein, wird der Algorithmus auch daran differenzieren. Nutzt man hingegen mehr Stammdaten, werden diese eher im Fokus der Gruppenbildung stehen.
Alternativ kann man auch naiv alle Daten rund um seinen Kunden oder Partner einspeisen und unseren Algorithmus entscheiden lassen, welche Attribute sich am ehesten zur Gruppenbildung eignen.
Case Studies

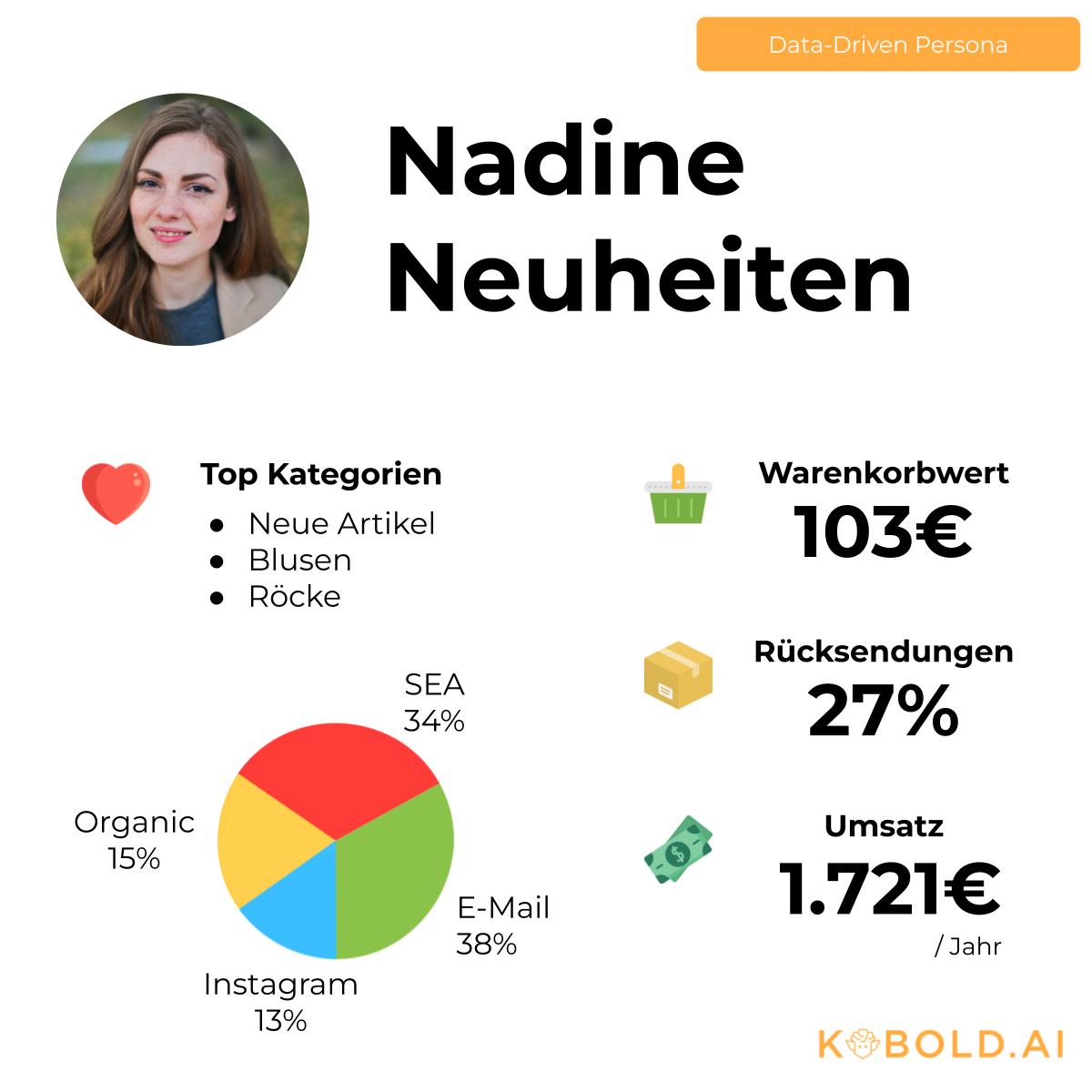
UDO BÄR: Der B2B-Betriebshändler nutzt Data-Driven Personas für seine Multichannel-Strategie

Funktionieren Data Driven Personas nur für Endkunden?
Nein! Wie qualitative Personas können Data-Driven Personas auch für Unternehmen (B2B), Lieferanten, Service-Partner und vieles mehr erstellt werden. Im Prinzip alle Entitäten, hinter denen Personen stehen.
“Durch das tiefgreifende Verständnis über die Bedürfnisse und das Kaufverhalten unserer Kunden sind wir in der Lage, unser Leistungsspektrum noch zielgerichteter an unseren Zielgruppen auszurichten.”
Thorsten Louis, CEO, BÄR Gruppe
Einsatz von datenbasierten Personas
Bleibt die Frage: Wie können datenbasierte Personas effektiv im Unternehmen eingesetzt werden? Unsere Erfahrung zeigt, dass sie in einer Bandbreite an Anwendungsfällen eingesetzt werden können:
- Marketing: Ein klares Verständnis von Kundengruppen erlaubt es, gezielte und personalisierte Kampagnen auszuspielen. Ein perfektes Beispiel ist ein Persona-bezogener Newsletter, der sich entsprechend der Vorlieben der zugrunde liegenden Kunden gestaltet und zu höherer Öffnungs- und Bestellrate führt.
- Kundenservice: Oft werden Anfragen, die im Service aufschlagen, komplett egalitär behandelt. Doch haben verschiedene Personas verschiedene Bedürfnisse. Folglich macht es Sinn, auch hier nach Personatyp zu unterscheiden und entsprechende Maßnahmen zu ergreifen.
- Aussendienst: Mit welcher Art von Kunde oder Unternehmen man es gleich zu tun haben wird, erleichtert es dem Aussendienst schon vorher zu wissen, was positiv zur Interaktion beiträgt. Zielgerichtete Angebote und höhere Effizienz sind die Folge.
- Produktentwicklung: Kundenzentriertes Denken ist der Kern einer nachhaltigen Produktentwicklung. Personas erlauben, die eigenen Kunden sehr konkret zu beachten, wenn es darum geht sein Sortiment zu optimieren und Innovation zu treiben.
- Einkauf: Viele Unternehmen entwickeln Produkte und Services, andere kaufen sie ein. Daher profitiert auch der Einkauf von einem Verständnis der Kunden einerseits, andererseits aber zusätzlich von der (erwarteten) Entwicklung dieser Kundengruppen.
Fazit: Künstliche Intelligenz für bessere Personas?
Ob Data-Driven Personas via künstlicher Intelligenz besser sind als qualitative wagen wir nicht zu beurteilen. Es ist eine fundamental andere Art und Weise, Personas zu erstellen. Und zwar sehr wahrheitsnah, getreu echter Verhaltensdaten und quantifizierbar.
Der ultimative Vorteil den wir für unsere Data-Driven Personas sehen ist die unmittelbare Anwendung: Dadurch, dass jeder Eintrag (= Ein Kunde / Lieferant / Partner) direkt in eine Gruppe eingeordnet wird, können die Ergebnisse ohne Umwege eingesetzt werden: Personalisierte Newsletter, unterschiedliche Marketing-Kampagnen und vieles mehr.
Zusammengefasst empfehlen wir, einfach mal datenbasierte Personas auszuprobieren: Produkt bestellen, Daten hochladen, Ergebnisse bekommen. So einfach.
Erwartetes Eingabeformat
Wir erwarten das folgende Eingabeformat:
- Spalten: Jede Spalte enthält ein Attribut
- Zeilen: Jede Zeile repräsentiert einen Kunden / Benutzer / Partner
- Beispielhafte Eingabedatei anzeigen
Ausgabe / Produktlieferung
Du musst angemeldet sein, um eine Rezension veröffentlichen zu können.






Rezensionen
Es gibt noch keine Rezensionen.