Kendra ist die neue Suchengine von Amazon Web Services (AWS), die den Zugang zu Informationen mittels Machine Learning erleichtern soll. Mit Kendra versucht Amazon weitere Teile von digitalen Kanälen zu erobern, indem es eine direkte Konkurrenzposition zu anderen Unternehmen wie Google oder Microsoft einnimmt.
Inhaltsverzeichnis
Was ist der Suchservice Amazon Kendra von AWS?

Das Ziel von Kendra ist eine benutzerfreundliche Kombination von Daten mit fortgeschrittener natürlicher Sprachverarbeitung, um ein optimales Kundenerlebnis zu erreichen. Die Idee ist, dass Kendra sich auf Anfragen in natürlicher Sprache (z.B. “Was ist Amazon Kendra?”) statt einfacher Stichwort-Suchen (z.B. “AWS Kendra”) konzentriert und diese bestmöglich beantwortet.
Mittels maschinellen Lernen versucht Kendra dann aus allen verknüpften Datenquellen die bestmögliche Antwort zu extrahieren, auszuliefern und die wichtigsten Informationen zu markieren. Dieses Vorgehen folgt der Entwicklung der Google Suche, die seit geraumer Zeit nicht mehr nur einfach ein Dokument ausspuckt, sondern bereits anzeigt, welche Information innerhalb des Dokuments ausschlaggebend für den Sucherfolg waren.
Herausforderungen in der Content-Suche
Amazon Kendra versucht Suche, vor allem Volltext-Suche im Contentbereich, elegant zu lösen. Um die Vorteile von Kendra zu verstehen, muss man erst einige der Herausforderungen in der Content-Suche verstehen:
Big Data in der Suche: Große und sich schnell ändernde Datenmengen
Mit zunehmender verfügbarer Datenmenge für die Suche ändern sich auch die Herausforderungen an das Suchsystem selbst. Eine Volltextsuche auf allen Dokumenten live auszuführen genügt seit geraumer Zeit nicht mehr, stattdessen sind Hash Tables ins Zentrum des Cachings gerückt. Diese Hash Tables – konstruiert aus relevanten Worten innerhalb von Dokumenten – zeigen auf, welche Begriffe in welchen Dokumenten gefunden werden können.
Während diese Herangehensweise ein schnelles Matching von Anfrage zu Ergebnis erlaubt, ist dieser Zwischenschritt dennoch kostenintensiv bei der Erstellung der Tables. Da sich im Zeitalter von Big Data und nutzergenerierten Daten sich die Datenbasis auch zunehmend schnell ändert, muss sich um die technische Komponente von Updates frühzeitig gekümmert werden.
Hier gibt es prinzipiell zwei Methoden: Ein full re-index vs. change log tables. Ersteres ist wie der Name bereits sagt die Herangehensweise, dass der Index in den Hash Tables komplett neu aufgebaut wird (z.B. Nachts als Batch Process), während zweiteres nur Veränderungen in der Datengrundlage als Grundlage für ein Update des Hashs nutzt. Ersteres ist einfacher zu implementieren und macht sicherlich Sinn bei kleineren Datenmengen, zweiteres hingegen ist komplexer aber erlaubt Erweiterung des Suchindexes auch bei laufenden Betrieb.
Als letztes ist die Infrastruktur im Blick von Suchservices. Mit zunehmenden Anfragen muss man sich Gedanken über die Skalierung der zugrundeliegenden Architektur machen. Speziell NoSQL-Systeme wie MongoDB gelten als Antwort auf solche Probleme, die durch RDMBS-Systeme nicht gelöst werden können.
Das beste Suchergebnis ausgeben: Such-Intent vs. Such-Ergebnis
Aber nicht nur die technische Grundlage der Datenverfügbarkeit und Suchanfrageabwicklung ist von Relevanz, sondern im Herz eines Suchergebnisses ist die möglichst optimale Auslieferung von Ergebnissen an den Nutzer. Der Such-Intent ist hierbei die Grundwahrheit (z.B. ein Nutzer möchte ein weißes Fahrrad), während die Such-Eingabe (z.B. “weißes Rad”) nicht immer eindeutig diesen Sinn widerspiegelt (möchte er ein Fahrrad oder ein Einzelrad?).
Um den Intent möglichst optimal mit einem Ergebnis zu bedienen, gilt es generell alle zur Verfügung stehenden Daten (Produktinformationen, Verhaltensdaten, Analyticsdaten, etc) zu gewichten und entsprechend der Anfrage auszuspielen. Hierbei können ein Ranking-Cocktail (z.B. der Titel ist relevanter als die Beschreibung), Frequenzen (z.B. welche Ergebnisse werden häufiger geklickt) oder auch Methoden der natürlichen Sprachverarbeitung (z.B. TF-IDF) und Machine Learning (z.B. Neuronale Netze) zum Einsatz kommen.
Gemeint aber nicht geschrieben: Synonyme, Abkürzungen, Tippfehler in der Suchanfrage
Als letztens großen Aspekt in der Content-Suche gilt es, auch unklare Nutzeranfragen aufzulösen und entsprechend auf mögliche Ergebnisse zu transferieren. Obiges Beispiel mit den Hash-Tables würde zum Beispiel die Anfrage “aws kendra” nicht auf “Amazon Web Services” mappen und somit kein valides Ergebnis zurückgeben.
Das gleiche gilt für Synonyme, Abkürzungen und Tippfehler. Um diese Herausforderungen zu lösen wird eine Vielzahl an Lösungen eingesetzt. Von phonetischer Suche (gegen Tippfehler) über Business Rules (um Synonyme fix anzulegen), statistische Methoden (z.B. Fuzzy Search) bis zu Machine Learning Modellen gibt es viele Lösungsansätze um auch schwierige, aber korrekte Suchanfragen zu verarbeiten.
Vorteile und Funktionen von AWS Kendra
Alle drei definierten Herausforderungen geht Kendra von Amazon Web Services durch ihre Grundfunktionalität ab.
Big Data & Skalierung von Kendra
Durch die direkte Integration in die Cloud Services von AWS ist Skalierungsfunktion kein Thema bei Kendra. Sowohl storage via S3 als auch Cloud Computing via EC2 oder Lambda sind nahezu unendlich skalierbar und somit gibt es keine Probleme, so man große Datenmengen nutzt und diese Datenmengen hochkomplex verarbeitet werden müssen. Generell erlaubt Kendra Zugriff auf alle gängigen Datenbanken mittels einer Vielzahl an Connectoren (momentan 17 gängige Connectoren: S3, file systems (SMB), Web crawler, Databases, SharePoint Online, SharePoint on prem, Box, Dropbox, Exchange, OneDrive, Google Drive, Salesforce, Confluence, Jira, Servicenow, Zendesk, Jive).
Suchintent vs. Suchergebnis Optimierung von Kendra
Der nächste Interessante Aspekt ist die Matching zwischen Suchintent und Suchergebnis. Diese Herausforderung ist der Kern von Kendra. Kendra hat zum Ziel, vor allem Antworten bei Fragen in natürlicher Sprache (z.B. “Welche Funktionen hat AWS Kendra?”) zu liefern. Der erweiterte Input einer natürlichen Fragestellung erlaubt der Suchmaschine, eine möglichst genaue Antwort zu suchen und finden. Aber auch bei einfachen Schlüsselwörtern (z.B. “Funktionen”) verknüpft Kendra die Blöcke in einem Dokument mit dem Nutzer.
Als Fallback-Mechanismus gibt es zusätzlich eine auf Deep Learning trainierte Ausgabe von URLs, die der Nutzer entsprechend verfolgen kann. Aber auch der “klassische” Weg, bestimmten Attributen in strukturierten Daten (z.B. Titel, Datum, Hits) mehr Gewicht zu verleihen („Ranking Cocktail“) ist bei Kendra möglich.
Alle Suchergebnisse basieren auf domänenspezifischen Modellen (zur Zeit für 16 Domänen verfügbar: industrielle Fertigung, IT, Rechtswesen, Finanzdienstleistungen, Tourismus und Hotellerie,Versicherungen, Pharmazeutika, Öl und Gas, Medien und Unterhaltung, Gesundheitswesen, Personalwesen, Nachrichtenwesen, Telekommunikation, Bergbau, Nahrungsmittel und Getränke und Automobilindustrie), was die Suchergebnisqualität noch weiter erhöht.
Synonyme, Abkürzungen und automatische Verbesserung der Ergebnisse
Während die beiden vorherigen Punkte bei Kendra von AWS bereits sehr gut abgedeckt werden, ist das Tool bei der letzten Herausforderung noch etwas schwach auf der Brust. Doch die Betonung liegt auf “noch” – denn die meisten dazugehörigen Funktionen sind als “in Kürze verfügbar” markiert (Stand: Juli 2020). So sollen sich Synonyme via Listen abdecken lassen, Amazon Kendra selbst lernen welche Ergebnisse gut passen und eine automatische Suchvervollständigung (sog. Suggest) einsetzen lassen
Besonders gespannt kann man auf die Analyse der Aktivitäten bei Kendra (z.B. mittels Tracking des Suchverhaltens und der Ergebnisqualität), da man dadurch schnell Schlüsse für den Erfolg der Suchengine ziehen kann. Amazon möchte hierzu eine Bandbreite an Metriken (z.B. häufigste Suchanfragen, beliebteste Ergebnisse, Qualitätsmetriken wie Mean Reciprocal Rank (MRR) und Bewertungen) bereitstellen, um die Optimierung des Systems zu unterstützen.
Was ist Kobold AI?
Kobold AI bietet den Einsatz künstlicher Intelligenz ohne technisches Vorwissen. Einfach, schnell und günstig KI anwenden, um Mehrwert durch Daten zu generieren.
Wie es funktioniert erklärt unser interaktives Video:
Tutorial: Technisches Setup von Amazon Kendra / Architektur und Infrastruktur
Das technische Setup von Amazon Kendra ist denkbar einfach. Im Endeffekt sind es zwei simple Schritte, bevor man bereits ins Testen und Anbinden gehen kann. Hier ein kurzes Tutorial um Kendra aufzusetzen:
Index als Basis für Datenquellen
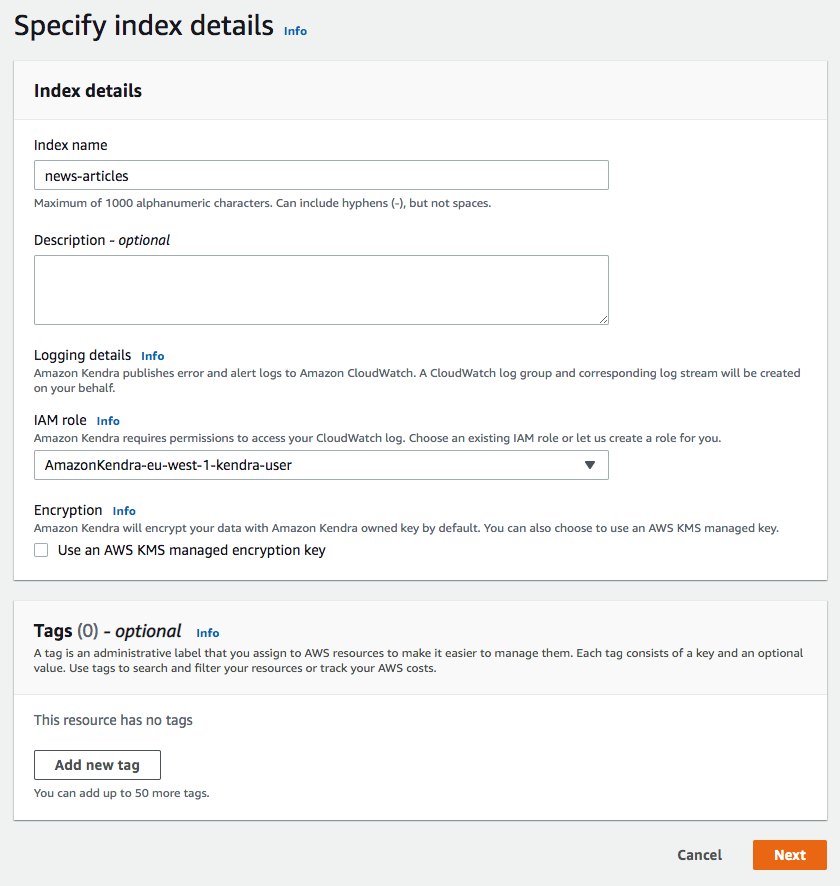
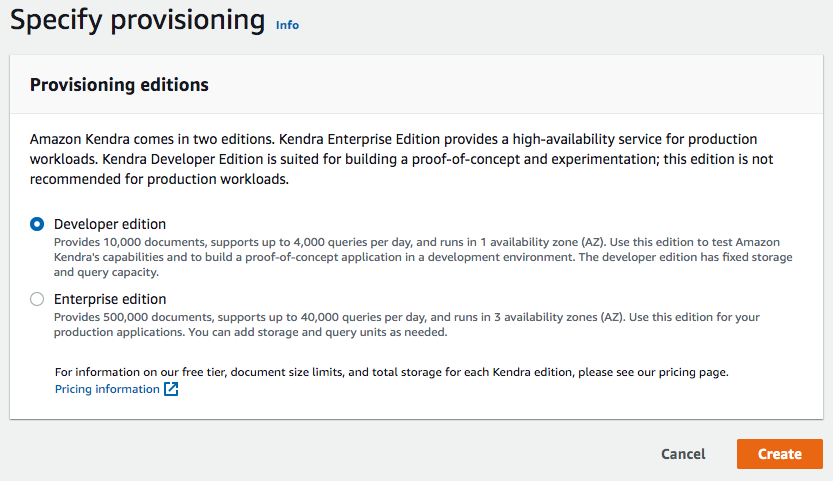
Der Index ist sozusagen der Container um die angebundenen Datenquellen. Es sind zwei einfache kurze Schritte und etwa 20 – 30 Minuten Wartezeit bis ein Index erstellt sind. Man gibt einfach einen Namen und eine IAM-Rolle an (Schritt 1), bevor man entscheidet ob es ein Developer oder Enterprise Index sein soll (Schritt 2). Schon wird der Index angelegt und nach einer gewissen Wartedauer (bis zu 30 Minuten) kann er genutzt werden.
Datenquellen als Grundlage für Suchergebnisse
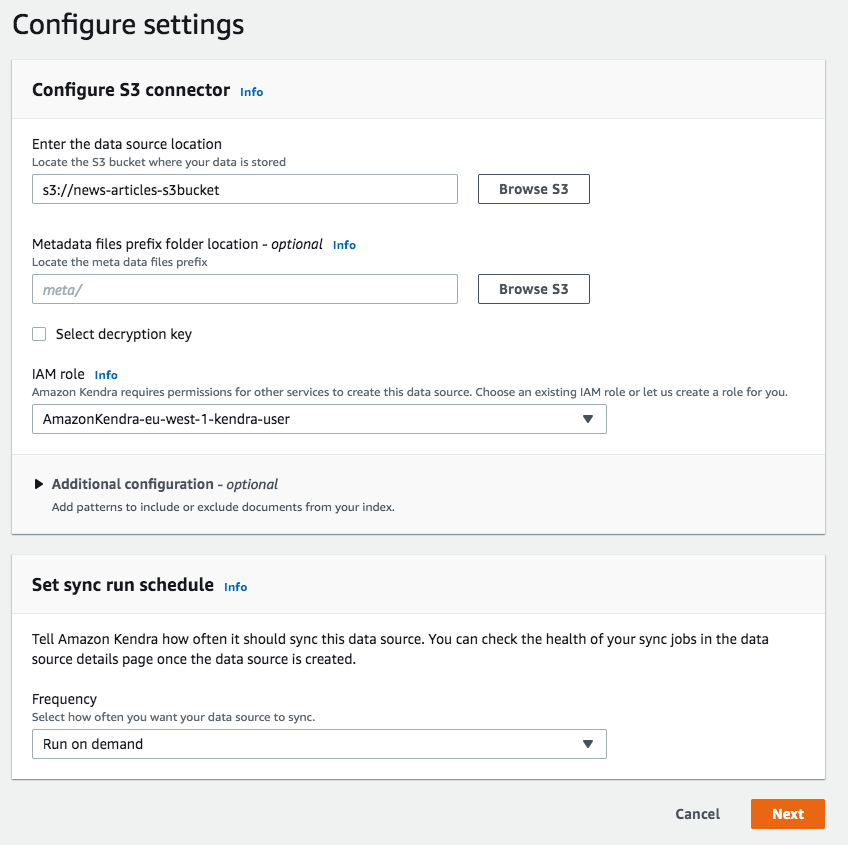
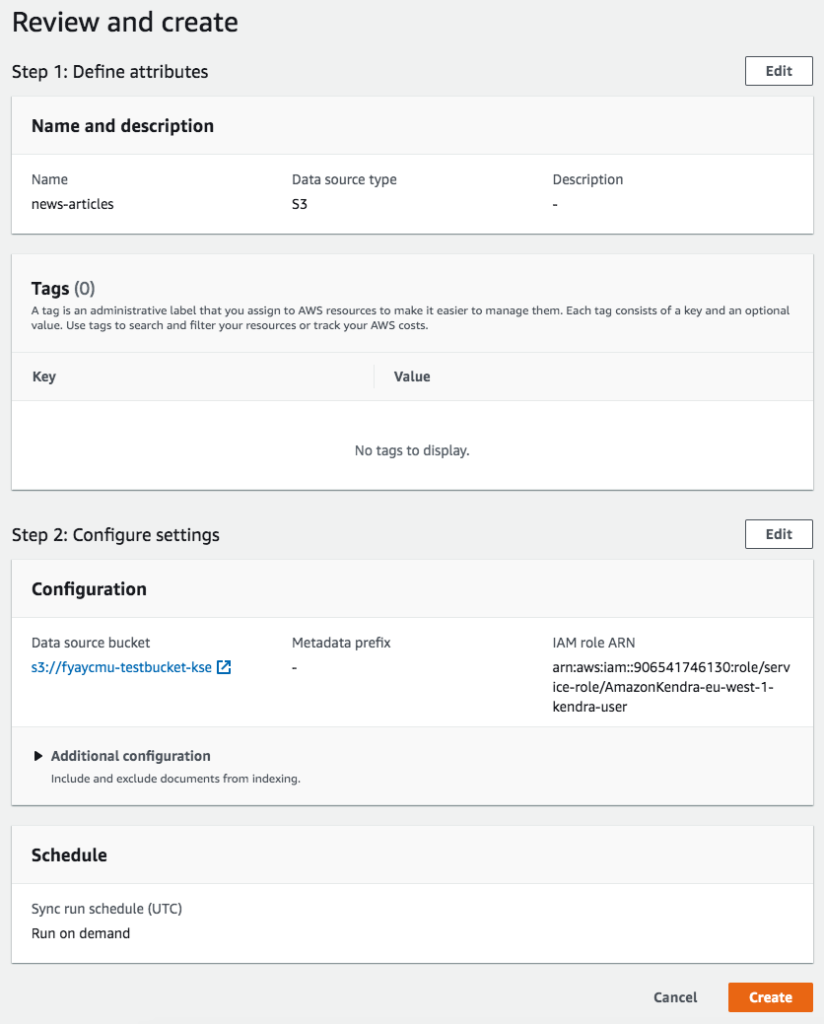
Als zweiter Schritt werden Datenquellen zum Index hinzugefügt. Man definiert den Namen der Datenquellen und wählt dann aus einem der zur Verfügung stehenden Konnektoren aus, wie man die Daten crawlen soll. Nach einem kurzen Review ist die Datenquelle angelegt und kann mittels “Sync now” synchronisiert werden.
Testen und Bereitstellen
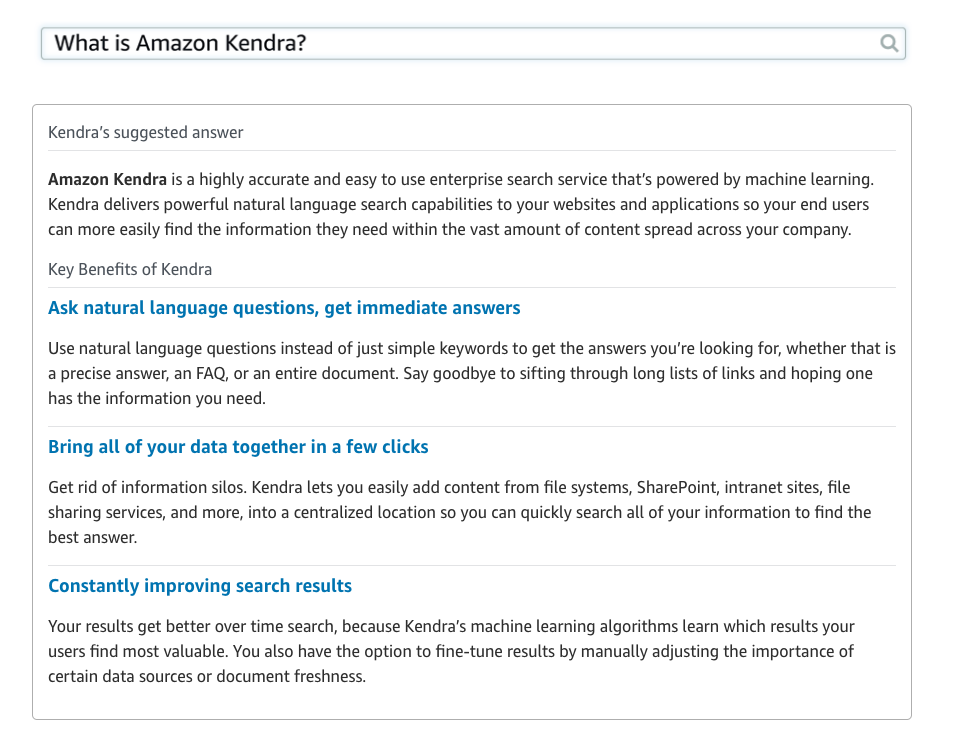
Voila. Das war’s und man kann die Daten mittels der bereitgestellten Tools durchsuchen und einbinden.
Preise von Amazon Kendra
Die Preisstruktur von AWS Kendra hängt primär vom Tier (Developer vs. Enterprise Edition) ab. Die Developer Edition hat zum Ziel, Proof of Concepts (POCs) zu erstellen, während die Enterprise Edition für den operativen Gebrauch gedacht ist. Somit hat man beim Developer Tier auch 750 kostenlose Stunden Uptime für den Index, in beiden Fällen zahlt man jedoch sowohl die Nutzung der Konnektoren als auch das Einlesen der Dokumente. Genauer hier als Tabelle:
| Kostenpunkt | Developer Edition | Enterprise Edition |
|---|---|---|
| Dokumente | 10.000 | 500.000 |
| Anfragen / Tag | 4.000 | 40.000 |
| Datenquellen | 5 | 50 |
| Kosten pro Stunde | $2.50 | $7 |
| Kosten pro Monat | $1.800 | $5.040 |
| Zusätzliche Queries | $3.50 / h für 40.000 / Tag | |
| Zusätzliche Dokumente | $3.50 / h für 500.000 Dokumente | |
| Scan je Dokument | $0.000001 | $0.000001 |
| Connectornutzung | $0.35 / h | $0.35 / h |
Beispiele für Anwendungen von AWS Kendra / Use Cases
Wie eingangs dargestellt gibt es viele Anwendungsfälle für den Einsatz von AWS Kendra. Vor allem alles, was größere Textmengen durchsucht eignet sich besonders gut in einer Kendra-Suche.
Interne Suche mittels AWS Kendra
Vor allem im Enterprise-Umfeld häufen sich die Suchanfragen nach Wissen in Dokumenten. Anwendungsfälle spannen sich von internen FAQs über Produktinformation, Forschungsunterlagen, Dokumentindexierung, internen Wissensdatenbanken bis zum Onboarding von neuen Mitarbeitern mittels umfangreichen Material.
Externe Suchanfragen durch Kendra, z.B. Onsite-Suche
Nebst der Optimierung der internen Suche ist die Königsdisziplin für jede Content-Suche jedoch die Bedienung von externen Kunden bzw. Interessenten. Ob im Support-Bereich, bei digitalen Produkten (z.B. Zeitschriften), e-Commerce-Beschreibungen, Content-Artikeln oder mehr: Den Nutzer schnell zum Ziel zu führen ist zentral, um ihn nicht zu verlieren.
Datenverwaltung mittels Indexierung von Kendra für eCommerce- oder Produktsuche
Während es Speziallösungen für die Suche innerhalb von Produktdaten gibt (z.B. Fredhopper), versucht AWS Kendra auch dieses Feld für sich zu erobern. Der Einsatzzweck wäre vor allem im E-Commerce-Bereich, also Onlineshops um das beste Produkt für den Interessenten zu finden.
Weitere Informationen und Video-Tutorial für Amazon Kendra
Was ist Kobold AI?
Kobold AI bietet den Einsatz künstlicher Intelligenz ohne technisches Vorwissen. Einfach, schnell und günstig KI anwenden, um Mehrwert durch Daten zu generieren.
Wie es funktioniert erklärt unser interaktives Video: