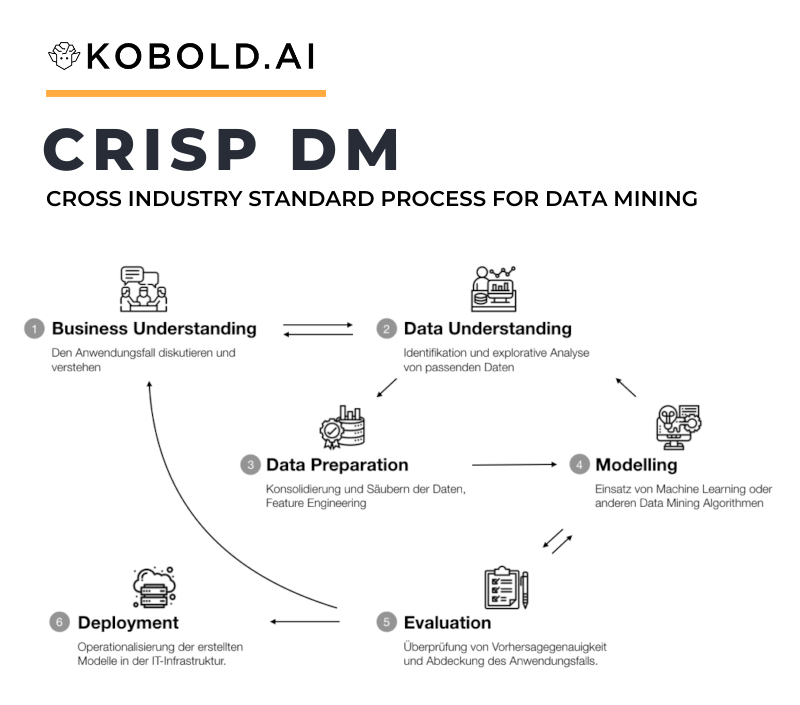
CRISP-DM steht für CRoss Industry Standard Process for Data Mining und ist ein standardisierter Prozess zur Durchführung von Data Mining. Er besteht aus sechs Phasen von dem Verstehen des Anwendungsfalls bis zur Operationalisierung des (Machine Learning basierten) Datenprodukts. In diesem Artikel möchten wir erklären wie der Prozess definiert ist, welche Rollen beteiligt sind und anhand eines Beispiels aufzeigen, wie man CRISP DM im Unternehmen einsetzen kann.
Inhaltsverzeichnis
Was ist das CRISP DM Modell?
CRISP DM steht für CRoss Industry Standard Process for Data Mining, auf Deutsch industrieübergreifender Standardprozess für Data Mining. Das Modell wurde entwickelt, um Data Mining in einzelne, einfach zu definierende Schritte zu unterteilen. Dies erlaubt es, klar zu strukturieren welche Aufgaben zu erledigen sind und wie man ein Projekt in Arbeitspakete unterteilen kann.
Genauer besteht CRISP-DM aus den Phasen “Business Understanding”, “Data Understanding”, “Data Preparation”, “Modeling”, “Evaluation” und “Deployment”. Folglich geht es darum, vom Anwendungsfall aus über die Daten den Use Case zu verstehen, die Daten entsprechend zu verarbeiten und dann zu prüfen, ob die Lösung operationalisiert werden kann.
Geschichte von CRISP DM
CRISP DM wurde in den 90iger Jahren als step-by-step Data Mining Guide entwickelt und präsentiert. Eines der Unternehmen das dieses Modell sehr fokussiert einsetzt ist IBM, welche in 2015 auch die Nachfolgemethode ASUM-DM (Analytics Solutions Unified Method for Data Mining) vorgestellt haben, der jedoch nicht an den Erfolg des Vorgängermodells anknüpfen kann..
In den letzten 25 Jahren hat sich CRISP-DM als Standard in vielen Unternehmen etabliert, die Data Mining betreiben. Dies geht so weit, dass es in mehreren Umfragen als führende Methode im Bereich Data Mining definiert wurde. Die Unternehmen die formell nicht CRISP-DM einsetzen, nutzen meist eine sehr ähnliche Variante die ähnlichen Schritten folgt, oft auch einfach als Data Science Prozess definiert.
Was ist Kobold AI?
Kobold AI bietet den Einsatz künstlicher Intelligenz ohne technisches Vorwissen. Einfach, schnell und günstig KI anwenden, um Mehrwert durch Daten zu generieren.
Wie es funktioniert erklärt unser interaktives Video:
Definition der sechs Phasen des CRISP DM Modells
Das CRISP DM Modell ist in sechs Phasen unterteilt, das wir im Folgenden näher darstellen:
Business Understanding: Verstehen des Anwendungsfalls

Am Anfang jedes Data Mining Projekts steht das Verstehen des Anwendungsfalls. Genauer gilt es in der Phase “Business Understanding” nicht nur den Use Case zu verstehen, sondern auch klar zu definieren auf welches Ziel hingearbeitet wird und welche Abnahmekriterien am Ende der Evaluation stehen.
Dieser Schritt in CRISP-DM wird oft unterschätzt und ist dennoch sehr zentral für den Erfolg jedes Projekts. Nur wenn ganz klar ist, wodurch Mehrwert für die internen Stakeholders generiert wird, arbeitet man nicht am Ziel vorbei. Im Optimalfall resultiert aus dieser strukturierten Vorgehensweise auch bereits in diesem Schritt ein Projekt- und Zeitplan. Dadurch ist eine enge Abstimmung zwischen technischer Fachabteilung von Data Scientists, Data Analysts und Data Engineers mit den Business Stakeholdern möglich.
Data Understanding: Explorative Datenanalyse

Als ersten Schritt auf dem Weg zur Erkenntnis werden die vorliegenden Daten explorativ auf Verarbeitbarkeit, Inhalt und Qualität untersucht. Da Data Mining sich im Generellen immer auf vorliegende Daten bezieht, sollten vor diesem Schritt bereits alle Data Engineering Arbeiten abgeschlossen sein und die Daten einfach einlesbar vorliegen.
Ziel der Phase “Data Understanding” ist es, einerseits die technische Machbarkeit zu prüfen, andererseits bereits hier einen guten Überblick über mögliche Einsatzzwecke der Daten im Bezug auf den Anwendungsfall der durch “Business Understanding” definiert wurde zu bekommen.
Data Preparation: Vorbereitung der Daten

Die Dara Preparation umfasst im wesentlichen drei Teile: Auswahl und Zusammenführung der Daten, Data Cleansing und Feature Engineering. Alle drei Teile basieren auf den Erkenntnissen der beiden vorhergehenden Phasen und sind im Prinzip die technische Umsetzung der vorher festgelegten Theorie.
Bei der Auswahl und Konsolidierung der Datenquellen gilt es, entsprechend dem Data Understanding die vorliegenden Datenquellen sinnvoll zusammenzuführen. Dies bildet die Basis für die folgenden Schritte des Data Cleansing und Feature Engineering.
Im Data Cleansing ist das Ziel, die Daten von niedriger Datenqualität zu befreien. Vor allem Ausreisser, fehlende Daten und falsche Daten beeinflussen die Qualität des Modelings stark. Um Data Cleansing erfolgreich durchzuführen benötigt es wiederum Input vom Business, damit klar ist, welche Inhalte korrekt und welche zu korrigieren sind.
Als letzter Schritt in der Data Preparation wird das Feature Engineering durchgeführt. Hierbei wird aus den vorbereiteten Daten bezeichnende Variablen konstruiert, die möglichst nah an dem zu betrachtenden Anwendungsfall sind. Diese konstruierten Variablen basieren auf den Erfahrungen, die in der Phase “Data Understanding” getroffen wurden und werden im nächsten Schritt, dem Modeling, eingesetzt.
Modeling: Erstellung des Modells

Die Modellierung – also eine statistische Gleichung für die vorhandenen Daten aufstellen – ist der Kern des CRISP DM Prozesses. Meist werden in diesem Schritt Methoden aus der Bereich des maschinellen Lernens (z.B. Supervised Learning) eingesetzt, um ein prädiktives Modell auf Basis der historischen Daten zu generieren. Dies wird vor allem mit zunehmenden Datenmengen die präferierte Herangehensweise. Aber auch eher diagnostische Modelle wie Interaktionsanalysen oder ANOVAs fallen in diese Kategorie.
Während dem Modeling werden also die in “Data Preparation” vorbereiteten Features verarbeitet, um schlussendlich Aussagen über gefundene Muster in den Daten zu treffen. Je nach Modell folgt diese Methodik dem Train-Test-Vorgehen, so dass die Daten in Trainings- und Testdatensätze geteilt werden, um den Erfolg des Modells iterativ zu verbessern. Hierbei findet die sogenannte Feature Selection statt, also die Auswahl von den Attributen die im vorhergehenden Schritt vorbereitet wurden, um eine möglichst hohe Prädiktionsrate zu erreichen.
Evaluation: Auswertung des Erfolgs

Während die letzten drei Schritte eher technischer Natur sind, ist in der Evaluationsphase wieder eine enge Zusammenarbeit zwischen den Data Scientists und den Business Stakeholdern gefragt. Nachdem das Modell erstellt und optimiert wurde, gilt es die Ergebnisse mit den Stakeholdern zu spiegeln.
Während die Evaluation des Modells selbst meist auf der Vorhersagegenauigkeit beruht, ist die Überprüfung des Erfolgs des Projekts meist weitreichender. Der Gesamtprozess wird nochmals analysiert, von Datenverfügbarkeit über Datenqualität bis zum Erfolg der Modellierung und der Diskussion der Aussagen, die sich davon ableiten lassen.
Schlussendlich gilt es in der Phase “Evaluation” zu entscheiden ob ein Deployment – also die Operationalisierung des Modells im Regelbetrieb – durchgeführt wird.
Deployment: Operationalisierung des Modells
Die letzte, finale Phase im CRISP-DM Prozess ist Operationalisierung des Modells, auch Deployment genannt. Hierzu wird das vorher trainierte oder erstellte Modell in die IT-Infrastruktur integriert, so dass es durchgehend in Betrieb ist.
Was dabei nicht vergessen werden darf ist die kontinuierliche Überwachung einerseits der Verfügbarkeit, andererseits der Performanz des Modells. Umso mehr Modelle im Betrieb sind, umso standardisierter werden diese Prozesse etabliert sein, was den letzten Schritt zunehmend einfacher gestaltet.
Was ist Kobold AI?
Kobold AI bietet den Einsatz künstlicher Intelligenz ohne technisches Vorwissen. Einfach, schnell und günstig KI anwenden, um Mehrwert durch Daten zu generieren.
Wie es funktioniert erklärt unser interaktives Video:
Welche Rollen sind am CRISP DM Prozess beteiligt?
Business Stakeholder / Domänenexperte
Business Stakeholder, also Mitarbeitende in der Domäne (zum Beispiel Fachabteilung, Produktmanager, Sales, Logistik, etc), sind vor allem in den Phasen Business Understanding und Evaluation beteiligt. Aber auch in Data Understanding und Data Preparation können sie durch ihr Fachwissen wertvolle Hinweise an die Fachexperten der Datenabteilung beisteuern.
Data Analyst
Datenanalysten bilden das Bindeglied zwischen Datenexperten und dem Business. Folglich sind sie vor allem am Anfang, im Business und Data Understanding beteiligt, unterstützen allerdings auch bei der Data Preparation und der Evaluation. Ihre Aufgabe ist die Aufbereitung und deskriptive Auswertung von Daten.
Data Engineer
Data Engineers extrahieren Daten, konsolidieren Datensätze und stellen sie zur weiteren Verarbeitung bereit. Daher sind sie am prominentesten vor dem Start des CRISP DM Prozesses indem sie die Infrastruktur und Daten bereit stellen, dann aber auch im Prozess selbst in der Phase Data Preparation. Kommt es zum Deployment, sind auch hier oft Data Engineers durch ihr Fachwissen starke Partner.
Data Scientist
Der Data Scientist ist in seiner Rolle im Prinzip in jeder der sechs Phasen des CRISP DM Prozesses beteiligt. Vor allem als Generalist arbeitet er vom Business Understanding über die Datenvorbereitung, seinem Kernbereich der Modellierung bis hin zum Deployment. Je nach Spezialisierung konzentrieren sich manche Data Scientists dabei eher auf businesszentrierte Arbeit, während andere ihre Stärken in der Datenanalyse und -modellierung sehen.
Machine Learning Engineer
Eine sehr starke Spezialisierung des Data Scientists ist der ML Engineer, der sich auf die Erstellung, das Training und die Optimierung von Machine Learning Modellen konzentriert. Daher ist seine Beteiligung vor allem im Modeling, oft aber auch in der Vorbereitung der Daten zu finden.
DevOps / MLOps / DataOps
Die klassische DevOps, neuer auch Abwandlungen im Sinne von MLOps oder Data Ops finden sich dann vor allem bei allen Aufgaben rund um das Deployment. Die Bereitstellung von Infrastruktur, einfügen in die unternehmensweite IT-Infrastruktur und andere Lösungen kommen aus der Feder dieser Experten.
Beispiel für den CRISP-DM Prozess im Einsatz

Ein einfaches Beispiel für den Einsatz des CRISP-DM Prozess möchten wir hier anhand von Predictive Maintenance, also der Vorhersage von Wartung bei Produktionsmaschinen, darstellen. Im Business Understanding muss hier klar der Anwendungsfall definiert werden: Um welche Maschinen geht es, welche Daten gibt es dazu, ist das Ziel Wartungswarnung oder erwartete Zeit bis zur Warnung (Klassifikation vs. Regression) und welche Ziele müssen erfüllt werden, damit ein Erfolg des Projekts gesehen wird.
Im Data Understanding ziehen dann Data Engineer, Data Analyst und Data Scientist die Datenquellen zusammen um zu verstehen welche Information vorhanden ist, um sie weiter zu verarbeiten. Welche Inhalte können extrahiert werden um eine Modellierung durchzuführen? Diese Frage gilt es an der Schnittstelle von Business Understanding und Data Preparation zu klären. Datenquellen im Bezug auf unser Beispiel wären die generelle Laufzeit, frühere Wartungsdaten, Sensordaten an relevanten Maschinenkomponenten, Produktionspläne und ähnliches.
Die Vorbereitung der Daten hat zum Ziel, klare Features aus den Daten zu extrahieren. Die Laufzeit in Stunden, die Wärmeentwicklung an bestimmten Komponenten der Maschine, die Belastung der Maschine, die zuständigen Mitarbeiter, das Alter der Maschine und vieles mehr kann einen Einfluss auf die Vorhersage der Wartungs haben.
Diese Features werden im Modeling genutzt, um eine Vorhersage zu erzielen. Predictive Maintenance nutzt üblicherweise KI Algorithmen aus der Kategorie Supervised Learning, im speziellen Klassifikation oder Regression. Um in unserem Beispiel zu bleiben, nehmen wir nun einen Random Forest als Classifier, ob die Maschine im kommenden Monat kaputt gehen wird oder nicht.
In der Evaluation kommen nun die am Projekt beteiligten zusammen und evaluieren die Ergebnisse. Hat der Algorithmus brauchbare Ergebnisse produziert, kann die notwendige Wartung also vorhergesagt werden? Sind die extrahierten Daten brauchbar? Wie könnte man einen erfolgreichen Algorithmus in Betrieb nehmen und wie werden Warnungen an das Wartungsteam ausgegeben?
Schließlich wird das Projekt zum Produkt und operativ verankert. Dazu wird Infrastruktur wie zum Beispiel ein Data Lake eingesetzt und mittels Containerising das ML-Modell ausgeführt um die Ergebnisse dann in einem Dashboard darzustellen. Von da an hat die Produktionssteuerung durchgehend eine Idee, welche Maschinen in Gefahr laufen, auszufallen und das Projekt ist erfolgreich abgeschlossen.
Nachteile von CRISP DM
Während CRISP-DM ein sehr strukturierter und häufig eingesetzter Prozess ist, hat er auch einige Lücken, auf die wir kurz eingehen möchten.
Kein Projektmanagement in CRISP DM
Einer der häufigsten Kritikpunkte an CRISP-DM ist, dass kein Projektmanagement eingedacht ist. Der Nachfolger ASUM-DM von IBM behebt dieses Problem, jedoch bleibt es im Originalprozess bestehen. Nichtsdestotrotz kann kontinuierliches Projektmanagement sicherlich hinzuorchestriert werden, so dass der Gesamtprozess von einer dedizierten Person gemanaged wird.
Datenakquisition wird nicht eingedacht
CRISP DM geht wie üblich im Data Mining davon aus, dass Daten vorhanden sind. Doch dies ist oft nicht der Fall: Entweder sind sie nicht erfasst, nicht im Unternehmen oder existieren noch gar nicht. Diese Data Acquisition ist mit CRISP DM nicht abgedeckt, sondern man startet immer mit der Annahme, dass genügend Daten für die erfolgreiche Durchführung der Phasen vorhanden sind.
Sehr linearer, eindimensionaler Prozess
Ein weiterer Kritikpunkt an CRISP ist, dass es ein relativ eindimensionaler Prozess ist. Während die Phasen nicht linear abgearbeitet werden, sondern selbstverständlich auch Rückschritte möglich sind (siehe Visualisierung), wird dennoch von einem Fortschritt durch die Phasen ausgegangen. Weiterhin wird komplett ignoriert, dass im agilen Arbeiten in vielen Anwendungsfällen erst ein Proof of Concept durchgeführt wird, bevor man diesen als vollständiges Datenprodukt umsetzt, was mit erheblich mehr Planung und Aufwand verbunden ist.
Warum der CRISP DM Prozess so relevant ist
Abschließend möchten wir kurz zusammenfassen, weshalb die CRISP DM Methode so relevant ist. Einfach gesagt hatte damals CRISP DM das Ziel, ein standardisiertes Verfahren zu etablieren. Dieser Standard hat drei Effekte: Einerseits strukturierter er das Vorgehen, so dass alle Phasen beachtet werden und keine groben Fehler gemacht werden. Dies erlaubt es hingegen als zweiten Effekt, dass das Vorgehen über mehrere Projekte vergleichbar ist. Als drittes ist ein solcher Standard vor allem auch der Professionalisierung eines damals noch sehr jungen Bereichs zuträglich.
Folglich sehen wir CRISP DM als sehr etabliertes und wichtiges Modell. Und selbst wenn nicht alle Unternehmen genau den Vorgaben der Methode folgen ist in den meisten Unternehmen jedoch ein Data Science Process etabliert, der dem Modell sehr ähnelt, da CRISP DM alle wichtigen Phasen abdeckt. Und ein solcher Prozess ist notwendig, um strukturiert und effizient mit dem Thema Data Science umzugehen.
Was ist Kobold AI?
Kobold AI bietet den Einsatz künstlicher Intelligenz ohne technisches Vorwissen. Einfach, schnell und günstig KI anwenden, um Mehrwert durch Daten zu generieren.
Wie es funktioniert erklärt unser interaktives Video: