
Dubletten in den Daten: Warum die Beseitigung von Duplikaten unerlässlich ist
In der heutigen digitalen Welt sammeln Unternehmen täglich eine enorme Menge an Daten. Diese Daten werden verwendet, um Entscheidungen zu treffen, Trends …
In der heutigen digitalen Welt sammeln Unternehmen täglich eine enorme Menge an Daten. Diese Daten werden verwendet, um Entscheidungen zu treffen, Trends …

Da die Welt von Tag zu Tag vernetzter und datengesteuerter wird, ist es für Fachleute in allen Bereichen unerlässlich, effektiv auf Daten …

Dieser Artikel ist ein umfassender Leitfaden zur generativen KI (englisch “Generative Artificial Intelligence”, GAI). Es diskutiert die Konzepte hinter der generativen KI, …

Wiederkäufer sind Kunden, die bereits einmal einen Kauf bei einem Unternehmen getätigt haben und erneut einkaufen. Sie sind von großer Bedeutung für …

Was ist Data Governance? Data Governance ist der Prozess der Verwaltung, Überwachung und Schutz von Daten innerhalb eines Unternehmens oder einer Organisation. …

Customer Lifetime Value (CLTV) definiert die zu erwartende Gesamtsumme an Umsatz von einem Kunden bzw. einer Gruppe an Kunden.
Der Decision Scientist nutzt Daten und Algorithmen um Entscheidungen zu treffen; Data Science wird auf dem Weg zur Optimierung als Werkzeug eingesetzt.

Der Data Steward ist eine neue Rolle, die mit der nachhaltigen Dokumentation, Qualitätskontrolle und Zugänglichkeit von Daten beauftragt ist.
Kaggle ist eine auf Wettbewerbe im Bereich Machine Learning spezialisierte Plattform, die mit oft sehr hohen Preisgeldern lockt.

Clustering bezeichnet die algorithmische Einordnung von Objekten, meist Daten, in Gruppen. Wir zeigen Methoden und Beispiele von Clusteranalysen.
Unstrukturierte Daten: Wie sind sie definiert und welche Rolle werden sie in Zukunft spielen? Wir erklären alles, was man dazu wissen muss.
Ein Data Warehouse speichert strukturierte Daten für analytische Verwendung. Wir definieren die Architektur und beantworten häufige Fragen.
Kendra ist die neue Suchengine von Amazon Web Services (AWS), die den Zugang zu Informationen mittels Machine Learning erleichtern soll. Mit Kendra …

Collaborative Filtering ist eine Algorithmenkategorie für Empfehlungssysteme, die das Verhalten einer Gruppe für Vorhersagen nutzt.

Edge Computing bezeichnet die Erfassung und Analyse von Daten direkt auf (mobilen) Geräten. Dazu zählen Mobiltelefone, Sensoren und mehr.
Es sprechen alle über Daten und deren Auswertung. Doch was sind eigentlich genau Daten und wie können sie definiert werden?
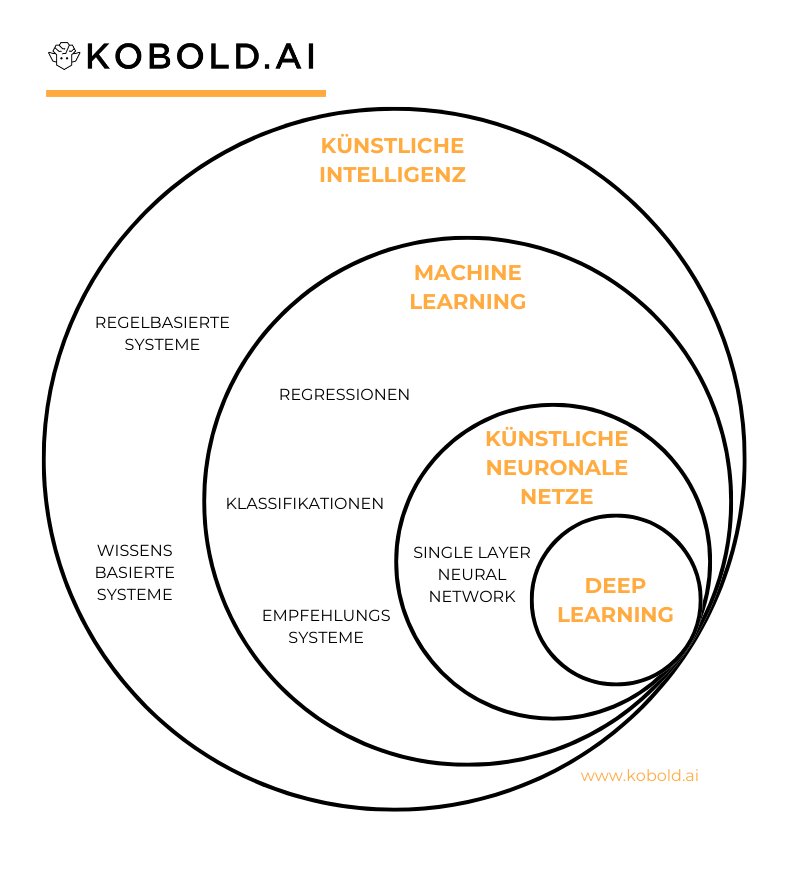
Machine Learning ist ein großes Feld mit einer Vielzahl an Methoden. Eine davon sind Neuronale Netze. Eine Unterart davon sind Deep Learning Netze.
Die Grundlage von neuronalen Netzen in der künstlichen Intelligenz sind Layer, die aus Input-Information abstrahieren können und somit nicht linear arbeiten.
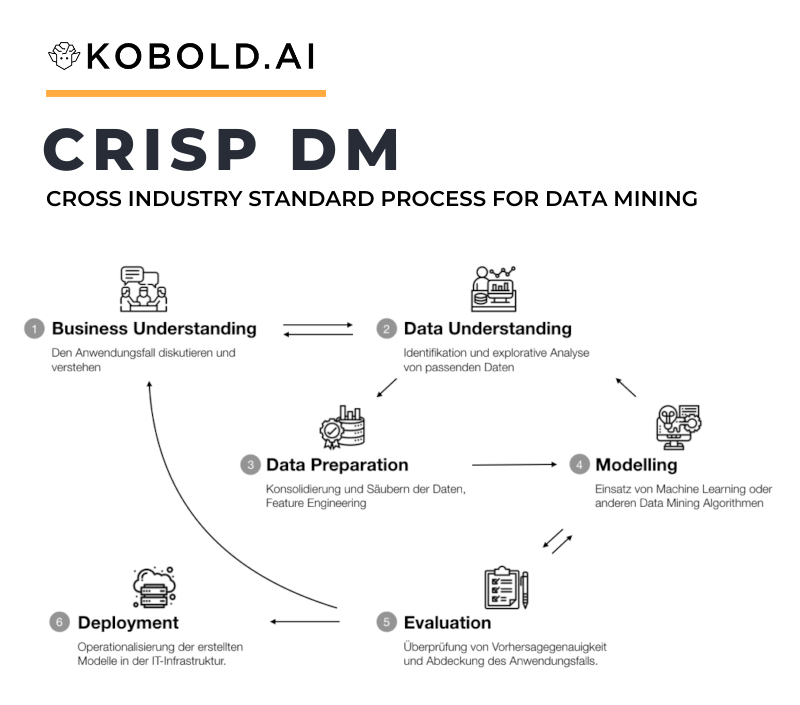
CRISP-DM steht für „CRoss Industry Standard Process for Data Mining“ und standardisiert den Einsatz von Data Mining durch 6 Schritte.
Google Data Studio ist eine kostenlose Visualisierungssoftware aus dem Hause Google. Doch was kann es und wo sind die Limits?

Big Data bezeichnet Daten die in Größe, Art oder Varianz nicht mehr einfach verarbeitet werden können. Der Einsatz von 6 Vs unterstützt bei der Definition.
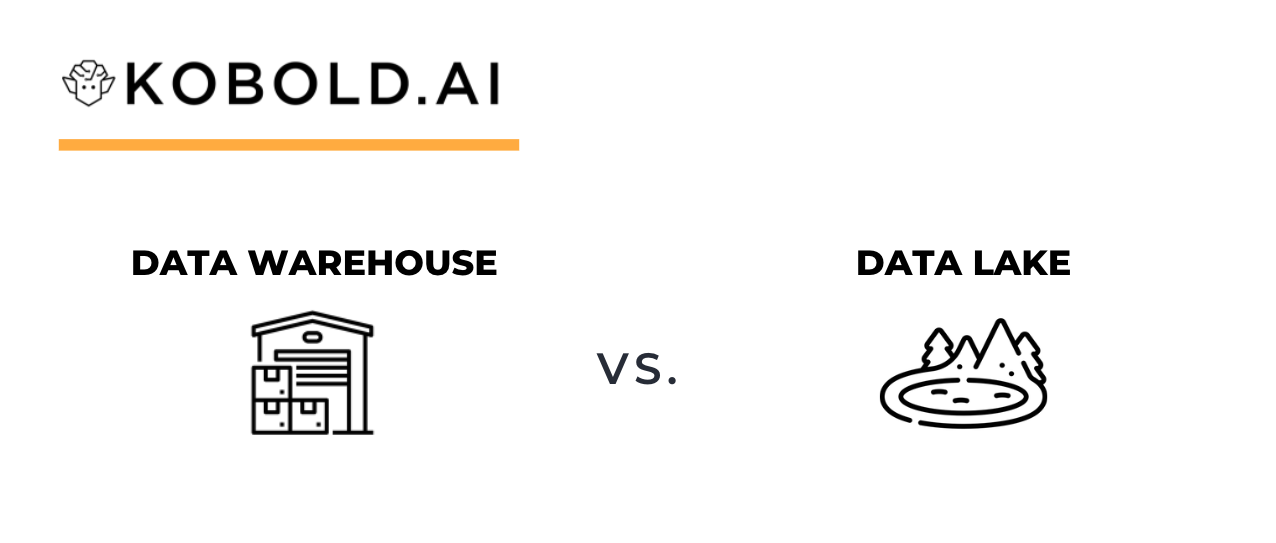
Einfach gesagt liegt der Unterschied zwischen einem Data Warehouse und einem Data Lake in Art der Daten, Pflege des Inhalts und Anwendungszweck.

Der Data Scientist agiert im Feld zwischen Datenvorbereitung, Analyse und künstlicher Intelligenz. Sein klares Ziel ist Mehrwert durch den Einsatz von Daten.

Die 6 Vs von Big Data sind Volumen, Velocity, Variety, Value, Variability und Veracity. Veracity definiert dabei die Qualität der Daten in Herkunft und Inhalt.

Die Datenwissenschaft gewinnt immer mehr an Relevanz. Hier geben wir eine klare Definition und zeigen Beispiele für die Anwendung von Data Science.

Das Internet of Things (Internet der Dinge) bringt physische Dinge in die digitale Welt und erlaubt neue Analysen, Services und Personalisierung.

Feature Engineering nennt man die Transformation von Rohdaten in passende Attribute für das Training eines Machine Learning Modells.

Data Mining ist die explorative Suche nach Mustern in großen Datensätzen. Dieser Artikel erklärt Definition, Methoden, Tools, Rollen und Probleme.

Was genau ist Big Data, welche Merkmale werden damit assoziiert und welche Technologien dafür eingesetzt? Diese Fragen beantwortet dieser Artikel.

Als Legacy System (deutsch: „Altsystem“) wird ein veraltetes System bezeichnet, das aufgrund des Aufwands noch nicht ersetzt wurde.

Big Data Value ist eines der Merkmale für Big Data. Dieser Wert definiert das Potential, Daten innovativ oder optimierend einzusetzen.

Künstliche Intelligenz bezeichnet Computerprogramme, die menschliches Verhalten nachahmen. Wir geben Einblick in Methoden und Beispiele.

Explainable AI (XAI) beschreibt die Herausforderung, dass das Ergebnis von Algorithmen der künstlichen Intelligenz für Menschen interpretierbar sind.

Synthetic Data beschreibt künstlich erzeugte Daten, die in Bereichen wie Machine Learning und Softwareprogrammierung eingesetzt werden.

Deepfakes sind durch künstliche Intelligenz erzeugte Inhalte (z.B. Videos), die sich von realem Material kaum unterscheiden lassen.

Smart Data sind Daten, die zur Nutzung in sowohl Datenqualität als auch Bereitstellung für Analysen und künstliche Intelligenz aufbereitet wurden.

Als Digital Twins bezeichnet man das digitale Abbild von realen Entitäten. Das Ziel ist die Kombination aller relevanten Daten und dazugehörige Analysen.

Ein Data Lake (Datensee) erfasst strukturierte und unstrukturierte Daten zur Weiterverarbeitung durch Data Science, Advanced Analytics und KI.

Datenqualität ist eines der bestimmenden Themen in vielen Unternehmen. Dieser Artikel vermittelt alles über Definition, Merkmale und Analyse was man wissen muss
Was sind Labels für Supervised Machine Learning? Wir definieren das Konzept und erklären, warum Labels so wichtig für überwachtes Lernen sind.

Data Staging bezeichnet im ETL-Prozess den Bereich der Extraktion und Transformation von Daten als Basis für ein Data Warehouse.

Digitalisierung bezeichnet die Umstellung von analog-manuellen Prozessen, Werkzeugen und Methoden auf digital-automatische.
Die Vorhersage der Abwanderung von Kunden, genannt Customer Churn Prediction, nutzt Daten und künstliche Intelligenz um gezielt Kunden ans Unternehmen zu binden

Batch Processing verarbeitet größere Datenblöcke, während Event Streams jede einzelne Information bearbeiten. Beide Big Data Methoden haben Vor- und Nachteile.

Citizen Data Scientists schließen die Lücke zu Data Science indem sie Wissen über KI-Methoden verfügen, aber nicht notwendig die Umsetzung selbst durchführen.

Data Governance ist die strategische und koordinierte Verwaltung von Daten. Wir stellen Merkmale, ein Framework und Beispiele vor.

Der Unterschied zwischen Data Analyst und Data Scientist liegt in Methoden, verarbeiteten Daten, genutzter Infrastruktur und Tools.
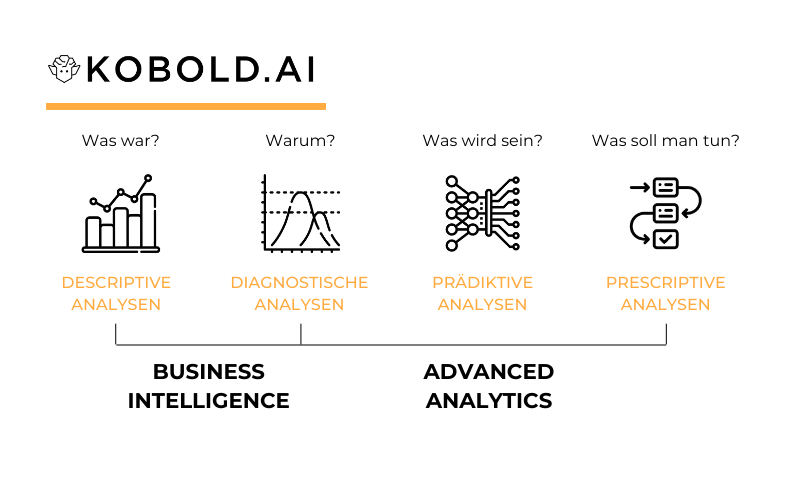
Advanced Analytics nutzt Daten und Künstliche Intelligenz um zu verstehen warum Dinge passieren, Prognosen zu erstellen und eine optimale Entscheidung zu geben.
Künstlicher Intelligenz, Maschinelles Lernen, Neuronale Netzwerke und Deep Learning sind hierarchisch aufeinander aufbauende Kategorien im Bereich KI.

Maschinelles Lernen (Machine Learning, ML) nutzt Algorithmen, um statistische Muster aus Daten zu extrahieren. Die Ziele sind Automatisierung und Vorhersagen.

Self-Supervised Learning nutzt Machine Learning um automatisch Labels für Algorithmen des überwachten Lernens zu generieren und einzusetzen.

Data Pipelines sind Skripte, die Daten von einem System in ein anderes überführt. Die Daten werden für weitere Verwendung (z.B. BI oder KI) bereitgestellt.

Was ist Data Driven Marketing? Wir definieren datengetriebenes Marketing und geben klare Beispiele, um die Vorteile aufzuzeigen.

Prescriptive Analytics ist die Empfehlung und Umsetzung von Handlungen basierend auf Datenauswertung mittels künstlicher Intelligenz.

Was ist Data Mining? In diesem Artikel geben wir eine einfache Erklärung und zeigen Anwendungsbeispiele wie Daten, Analysen und Data Science eingesetzt werden.

Die Hauptaufgabe eines Data Engineers ist die verlässliche Bereitstellung von Daten für Business Intelligence, Data Science und künstliche Intelligenz.

Die Aufgaben des Chief Data Officer (CDO) im Unternehmen liegen an der Schnittstelle von Datenhaltung („Defensive“) und Dateninnovation („Offensive“).

Einfach gesagt nutzt Machine Learning Daten, um Muster zu erkennen. Diese Muster werden eingesetzt um Vorhersagen (z.B. Ähnlichkeiten, Prognosen) zu erstellen.

Es gibt drei Arten von künstlicher Intelligenz: Stark, schwach und Superhuman. Manche sind noch weit entfernt real zu werden, andere hingegen schon im Einsatz.

Künstliche Intelligenz ist die Simulierung menschlicher Verhaltensweisen durch Maschinen. Wir erklären alles, was man zu KI wissen muss.

AI, KI, ML, DS und viele mehr Abkürzungen erobern die Welt der Daten. Doch manchmal ist nicht klar, wofür die Begriffe stehen …
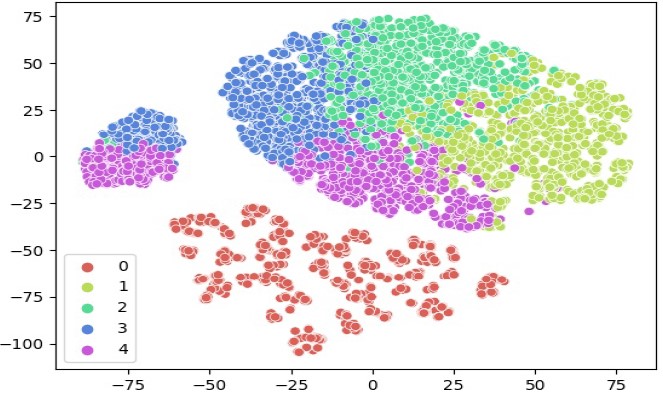
Ähnliche Dinge zu finden ist oft nicht einfach. Vor allem in einer immer größer werdenden Flut von Daten ist es herausfordernd, ähnliche …